Kaldi决策树状态绑定学习笔记二


Kaldi 决策树状态绑定学习笔记(二)
——如何自动生成问题集?
Kaldi 决策树中使用的问题集并不是手工设计的,而是通过之前得到的统计
量自动生成的。那么在 Kaldi 中是如何自动生成问题的?这就是本次笔记的主要
内容。
在这个笔记中,我会首先介绍自动生成问题集所用到的主程序 cluster-
phones 和主函数 AutomaticallyObtainQuestions(),然后会穿插着介绍主函数用到
的核心函数和完成具体工作的一些 C++对象。最后再讲解程序 compile-question。
建议学习 Kaldi 官方文档《Decision tree internals》的 Classes and functions
involved in tree-building 部分,《 How decision trees are used in Kaldi》的 The tree
building process 部分。
若对似然这些名词和对应的公式感觉陌生,请参考论文《Tree-Based State
Tying For High Accuracy Acoustic Modelling 》 S.J.Young 的 第 三 部 分 Tree-
BasedClustering。
cluster-phones
作用:Cluster phones (or sets of phones) into sets for various purpose. 对多个音
素或多个音素集进行聚类。
输入:决策树相关统计量 treeacc,多个音素集 sets.int
输出:自动生成的问题集(每个问题由多个音素组成)
示例:
cluster-phones $context_opts $dir/treeacc $lang/phones/sets.int \
$dir/questions.int
过程:
1. 从 treeacc 中 读 取 统 计 量 到 BuildTreeStatsType stats ;读取 vector
pdf_class_list,该变量指定所考虑的 HMM 状态,默认为 1,也就是只考虑
三状态 HMM 的中间状态;从 sets.int 读取 vector<vector> > phone_sets;
默认的三音素参数 N=3,P=1。
2. 若指定的 mode 为 questions,调用 AutomaticallyObtainQuestions()自动生
成问题集 vector<vector> > phone_sets_out;若指定的 model 为 k-means,
调用 KMeansClusterPhones()。此笔记只涉及 questions 模式。
3. 将上述函数自动生成的 phone_sets_out 写到 questions.int。
文件说明:
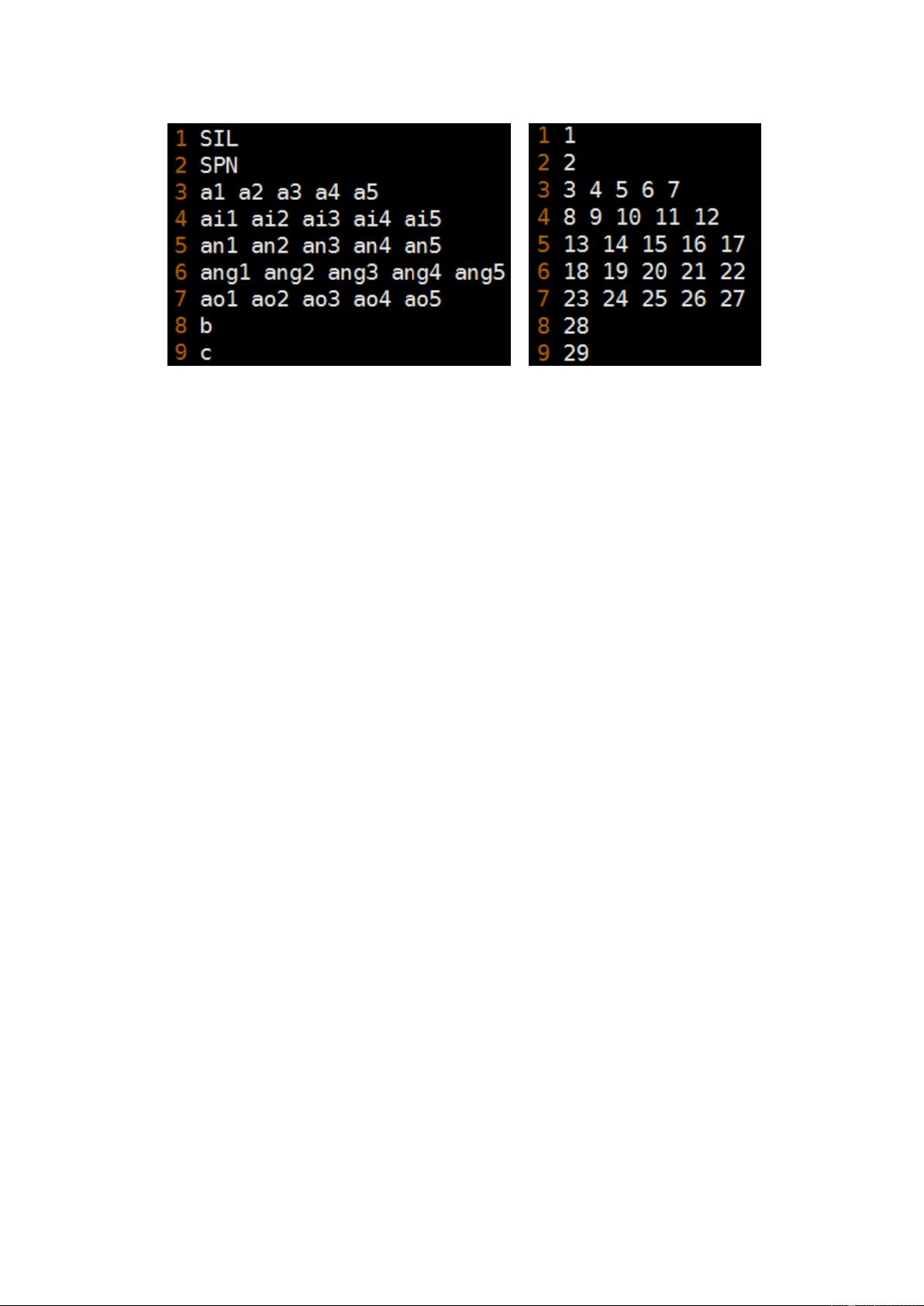
下面以我们实验室所用的 sets.int 和 sets.txt 为例,来对 sets.int 文件有一个直
观的感受:(左边是 sets.txt,右边是 sets.int,两图第一列均为行号)

剩余13页未读,继续阅读
资源评论

 gubinbing2018-07-10还是不错的
gubinbing2018-07-10还是不错的












