面向任务的对话系统的最新进展和挑战【清华大学】.pdf
需积分: 10 51 浏览量
2020-03-24
17:53:43
上传
评论
收藏 575KB PDF 举报


SCIENCE CHINA
Information Sciences
.
REVIEW
.
Recent Advances and Challenges in
Task-oriented Dialog System
Zheng Zhang, Ryuichi Takanobu, Minlie Huang
*
& Xiaoyan Zhu
Dept. of Computer Science & Technology, Tsinghua University, Beijing 100084, China;
Institute for Artificial Intelligence, Tsinghua University (THUAI), Beijing 100084, China;
Beijing National Research Center for Information Science & Technology, Beijing 100084, China
Abstract Due to the significance and value in human-computer interaction and natural language process-
ing, task-oriented dialog systems are attracting more and more attention in both academic and industrial
communities. In this paper, we survey recent advances and challenges in an issue-specific manner. We discuss
three critical topics for task-oriented dialog systems: (1) improving data efficiency to facilitate dialog system
modeling in low-resource settings, (2) modeling multi-turn dynamics for dialog policy learning to achieve
better task-completion performance, and (3) integrating domain ontology knowledge into the dialog model
in both pipeline and end-to-end models. We also review the recent progresses in dialog evaluation and some
widely-used corpora. We believe that this survey can shed a light on future research in task-oriented dialog
systems.
Keywords task-oriented dialog, low-resource, dialog state tracking, dialog policy, end-to-end model
Citation Zhang Z, Takanobu R, Huang M, Zhu X. Recent Advances and Challenges in Task-oriented Dialog
System. Sci China Inf Sci, for review
1 Introduction
Building task-oriented (also referred to as goal-oriented) dialog systems has become a hot topic in the
research community and the industry. A task-oriented dialog system aims to assist the user in completing
certain tasks in a specific domain, such as restaurant booking, weather query, and flight booking, which
makes it valuable for real-world business. Compared to open-domain dialog systems where the major
goal is to maximize user engagement [1], task-oriented dialog systems are more targeting at accomplishing
some specific tasks in one or multiple domains. Typically, the task-oriented dialog systems are built on
top of a structured ontology, which defines the domain knowledge of the tasks.
1.1 General Framework
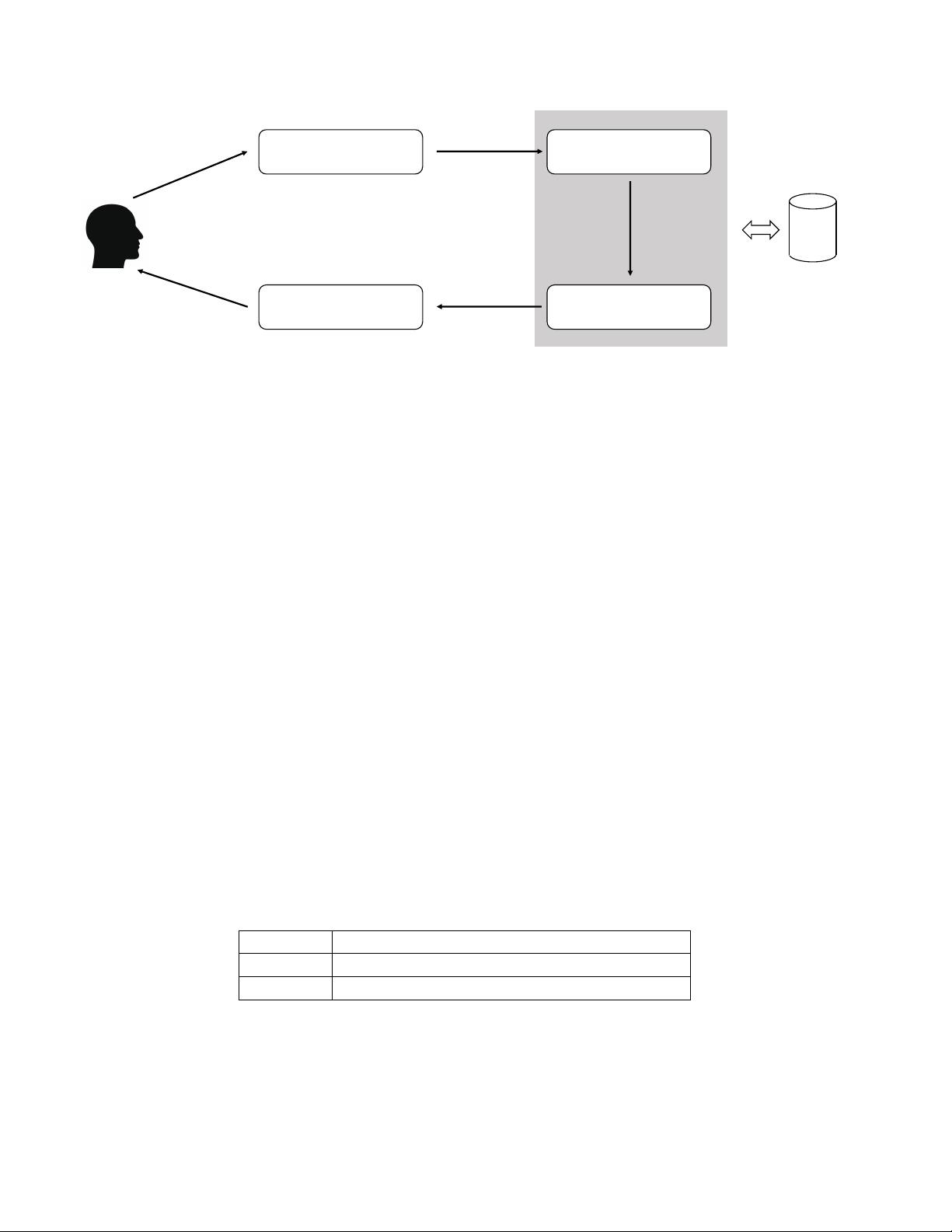
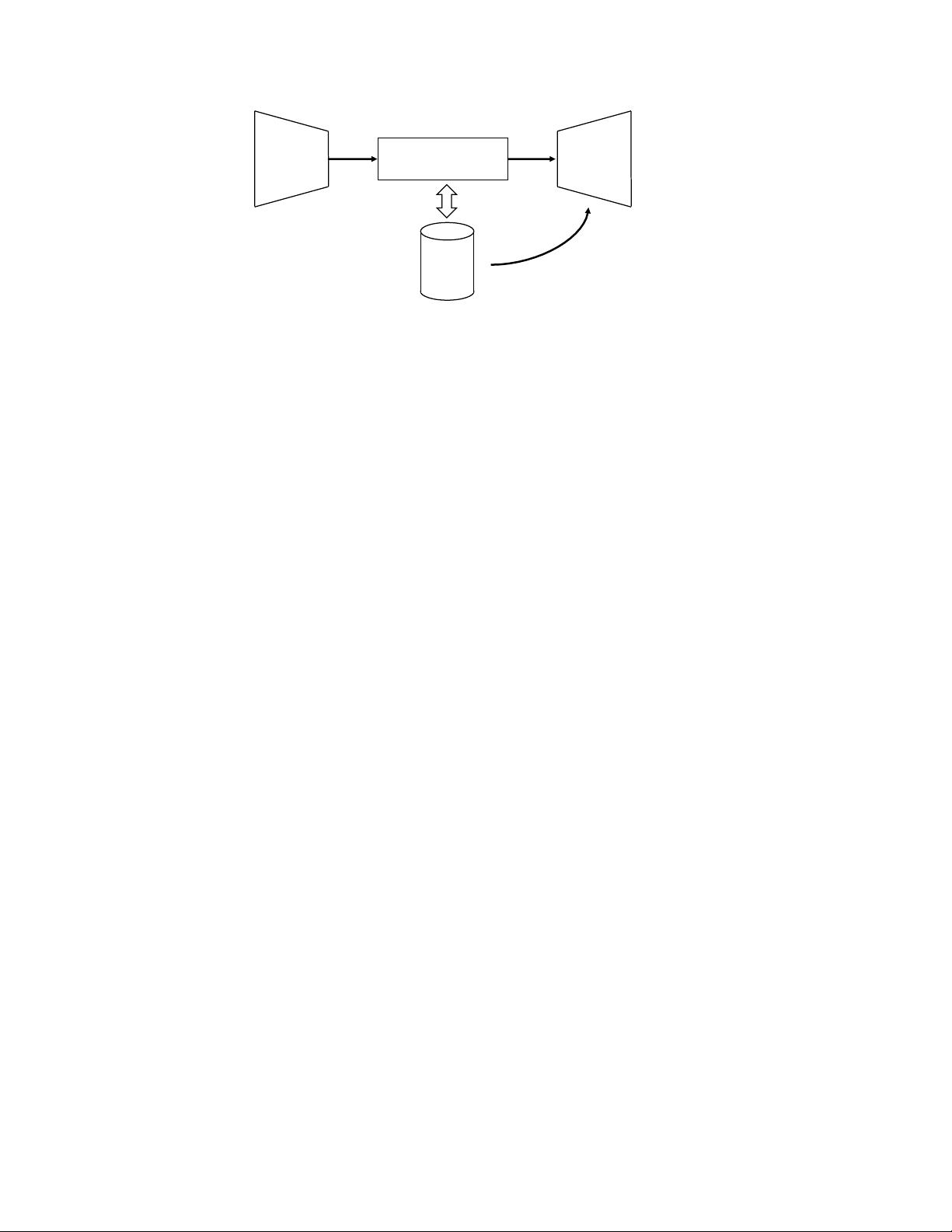
The architecture of task-oriented dialog systems can be roughly divided into two classes: pipeline and
end-to-end approaches. In pipeline approaches, the model often consists of several components, includ-
ing Natural Language Understanding (NLU), Dialog State Tracking (DST), Dialog Policy, and Natural
Language Generation (NLG), which are combined in a pipeline manner as shown in Figure 1. The NLU,
DST and NLG components are often trained individually before being aggregated together, while the
dialog policy component is trained within the composed system. It is worth noting that although the
NLU-DST-Policy-NLG framework is a typical configuration of the pipeline system, there are still some
* Corresponding author (email: aihuang@tsinghua.edu.cn)
arXiv:2003.07490v2 [cs.CL] 19 Mar 2020
剩余18页未读,继续阅读
资源评论













