


u 第二章
问答第 1 题
PL/0 语言允许过程嵌套定义和递归调用,它的编译程序在运行时采用了栈式动态存储管理。(数组
CODE 存放的只读目标程序,它在运行时不改变。)运行时的数据区 S 是由解释程序定义的一维整型数组,
解释执行时对数据空间 S 的管理遵循后进先出规则,当每个过程(包括主程序)被调用时,才分配数据空间,
退出过程时,则所分配的数据空间被释放。应用动态链和静态链的方式分别解决递归调用和非局部变量的
引用问题
问答第 2 题
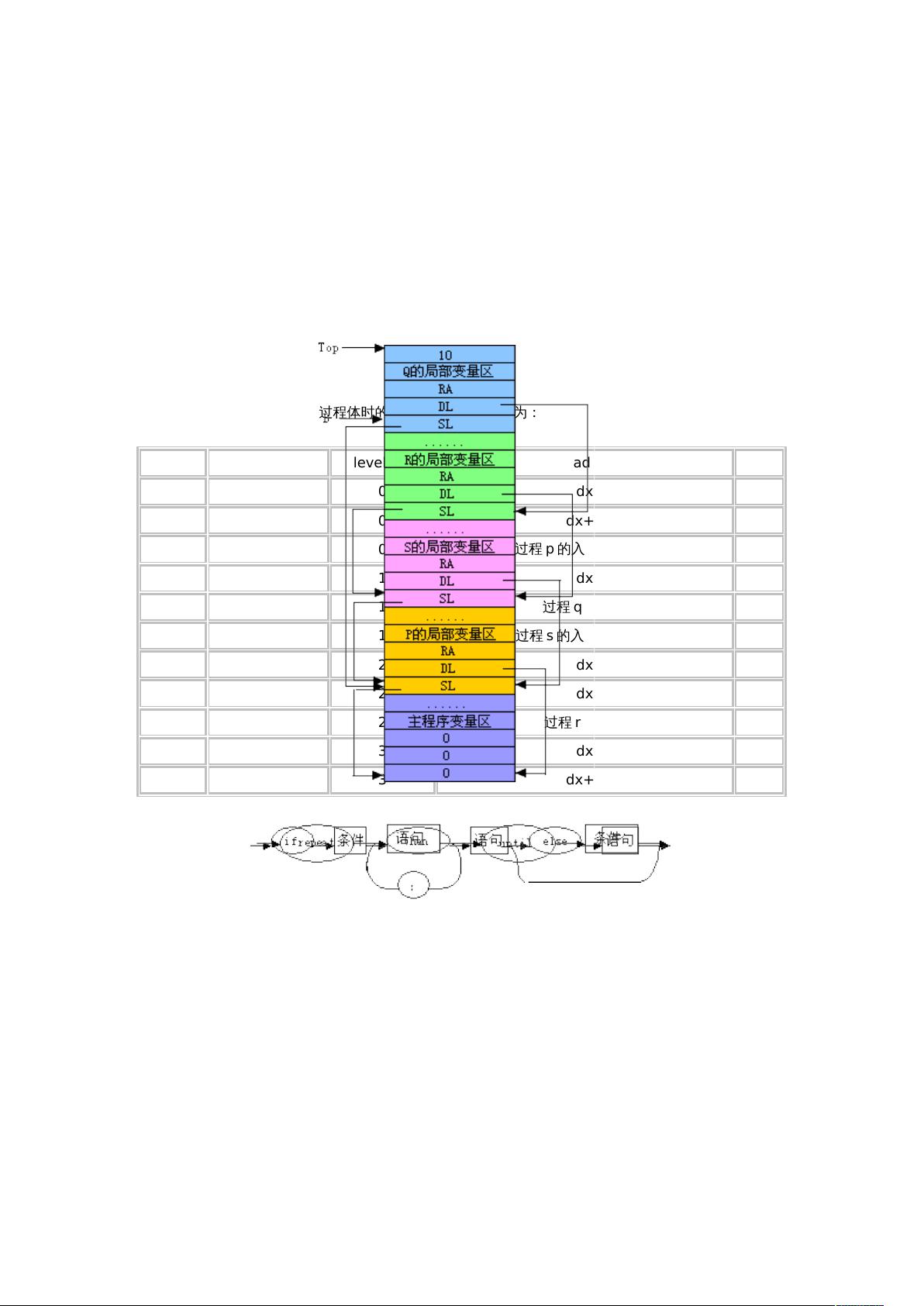
程序执行到赋值语句 b∶=10 时运行栈的布局示意图为:
问答第 3 题
题 2 中当程序编译到 r 的过程体时的名字表 table 的内容为:
name kind level/val adr size
x variable 0 dx
y variable 0 dx+1
p procedure 0
过程 p 的入口(待填)
5
a variable 1 dx
q procedure 1
过程 q 的入口
4
s procedure 1
过程 s 的入口(待填)
5
c variable 2 dx
d variable 2 dx
r procedure 2
过程 r 的入口
5
e variable 3 dx
f variable 3 dx+1
注意:q 和 s 是并列的过程,所以 q 定义的变量 b 被覆盖。
问答第 4 题
栈 顶 指 针
T , 最 新 活 动 记
录基地址指针 B,
动态链指针 DL,静态链指针 SL 与返回地址 RA 的用途说明如下:
T: 栈顶寄存器 T 指出了当前栈中最新分配的单元(T 也是数组 S 的下标)。
B:基址寄存器,指向每个过程被调用时,在数据区 S 中给它分配的数据段起 始 地址,也称基地址。
SL: 静态链,指向定义该过程的直接外过程(或主程序)运行时最新数据段的基地址,用以引用非
局部(包围它的过程)变量时,寻找该变量的地址。
DL: 动态链,指向调用该过程前正在运行过程的数据段基地址,用以过程执行结束释放数据空间时,
恢复调用该过程前运行栈的状态。
RA: 返回地址,记录调用该过程时目标程序的断点,即调用过程指令的下一条指令的地址,用以过
程执行结束后返回调用过程时的下一条指令继续执行。
在每个过程被调用时在栈顶分配 3 个联系单元,用以存放 SL,DL, RA。
问答第 5 题
















评论0