# Transformer:Seq2Seq 模型 + 自注意力機制
- [neural-machine-translation-with-transformer-and-tensorflow2](https://leemeng.tw/neural-machine-translation-with-transformer-and-tensorflow2.html)
- [Transformer 模型的 PyTorch 实现](https://juejin.im/post/5b9f1af0e51d450e425eb32d)
- [Google 在 2017 年 6 月的一篇論文:Attention Is All You Need](https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf)
- [Google AI Blog: transformer-novel-neural-network](https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)
- [ HarvardNLP 以 Pytorch 實現的 The Annotated Transformer](http://nlp.seas.harvard.edu//2018/04/03/attention.html#additional-components-bpe-search-averaging)
- [进击的BERT](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
- [OpenAI 的 GPT](https://openai.com/blog/better-language-models/)
- [机器翻译自动评估-BLEU算法详解](https://blog.csdn.net/qq_31584157/article/details/77709454)
- [Batch Normalization](https://www.cnblogs.com/shine-lee/p/11989612.html)
- [Layer Normalization Paper](https://arxiv.org/abs/1607.06450)
## 概念
循環神經網路 RNN 時常被拿來處理序列數據,但其運作方式存在著一個困擾研究者已久的問題:無法有效地平行運算。
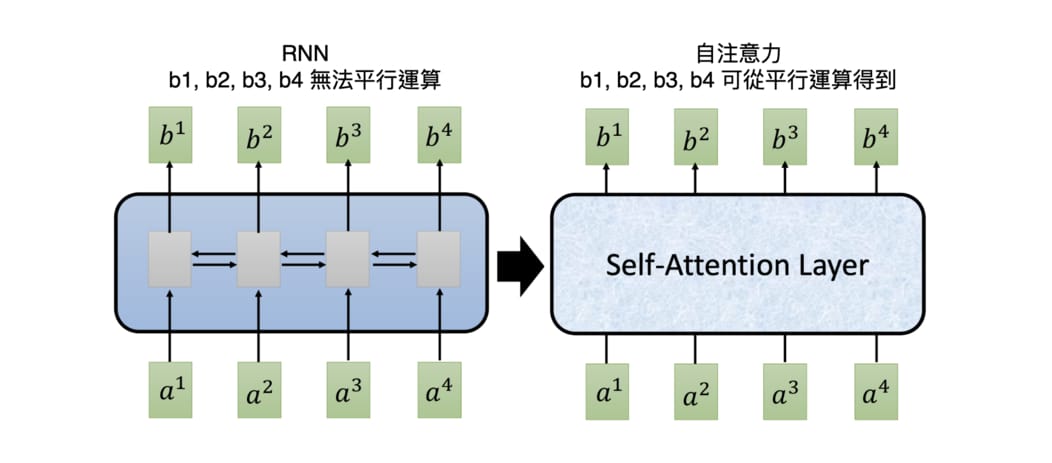
Google 在 2017 年 6 月的一篇論文:Attention Is All You Need 裡參考了注意力機制,提出了自注意力機制(Self-Attention mechanism)。這個機制不只跟 RNN 一樣可以處理序列數據,還可以平行運算。
一個自注意層(Self-Attention Layer)可以利用矩陣運算在等同於 RNN 的一個時間點內就回傳所有 bi ,且每個 bi 都包含了整個輸入序列的資訊。相比之下,RNN 得經過 4 個時間點依序看過 [a1, a2, a3, a4] 以後才能取得序列中最後一個元素的輸出 b4 。
雖然我們一直強調自注意力機制的平行能力,如果你還記得我們在上一節講述的注意力機制,就會發現在 Seq2Seq 架構裡頭自注意力機制跟注意力機制講的根本是同樣一件事情:
- 注意力機制讓 Decoder 在生成輸出元素的 repr. 時關注 Encoder 的輸出序列,從中獲得上下文資訊
- 自注意力機制讓 Encoder 在生成輸入元素的 repr. 時關注自己序列中的其他元素,從中獲得上下文資訊
- 自注意力機制讓 Decoder 在生成輸出元素的 repr. 時關注自己序列中的其他元素,從中獲得上下文資訊
總之透過新設計的自注意力機制以及原有的注意力機制,Attention Is All You Need 論文作者們打造了一個完全不需使用 RNN 的 Seq2Seq 模型:Transformer。以下是 Transformer 中非常簡化的 Encoder-Decoder 版本,讓我們找找哪邊用到了(自)注意力機制:
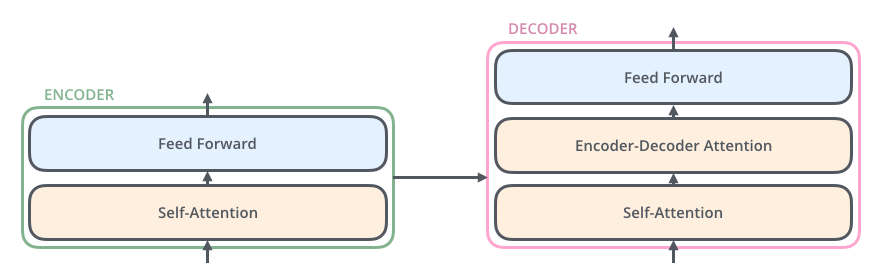
在 Transformer 裡頭,Decoder 利用注意力機制關注 Encoder 的輸出序列(Encoder-Decoder Attention),而 Encoder 跟 Decoder 各自利用自注意力機制關注自己處理的序列(Self-Attention)。無法平行運算的 RNN 完全消失,名符其實的 Attention is all you need.
以 Transformer 實作的 NMT 系統基本上可以分為 6 個步驟:
- Encoder 為輸入序列裡的每個詞彙產生初始的 repr. (即詞向量),以空圈表示
- 利用自注意力機制將序列中所有詞彙的語義資訊各自匯總成每個詞彙的 repr.,以實圈表示
- Encoder 重複 N 次自注意力機制,讓每個詞彙的 repr. 彼此持續修正以完整納入上下文語義
- Decoder 在生成每個法文字時也運用了自注意力機制,關注自己之前已生成的元素,將其語義也納入之後生成的元素
- 在自注意力機制後,Decoder 接著利用注意力機制關注 Encoder 的所有輸出並將其資訊納入當前生成元素的 repr.
- Decoder 重複步驟 4, 5 以讓當前元素完整包含整體語義
## 应用
- 文本摘要(Text Summarization)
- 圖像描述(Image Captioning)
- 閱讀理解(Reading Comprehension)
- 語音辨識(Voice Recognition)
- 語言模型(Language Model)
- 聊天機器人(Chat Bot)
- 其他任何可以用 RNN 的潛在應用
## 模型架构
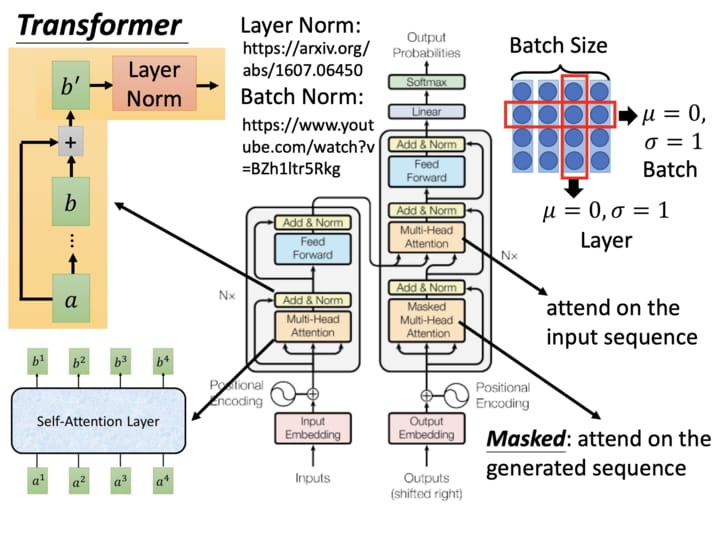
### Transformer
- Encoder
- 輸入 Embedding
- 位置 Encoding
- N 個 Encoder layers
- sub-layer 1: Encoder 自注意力機制
- sub-layer 2: Feed Forward
- Decoder
- 輸出 Embedding
- 位置 Encoding
- N 個 Decoder layers
- sub-layer 1: Decoder 自注意力機制
- sub-layer 2: Decoder-Encoder 注意力機制
- sub-layer 3: Feed Forward
- Final Dense Layer
### Word Embedding
词向量模型
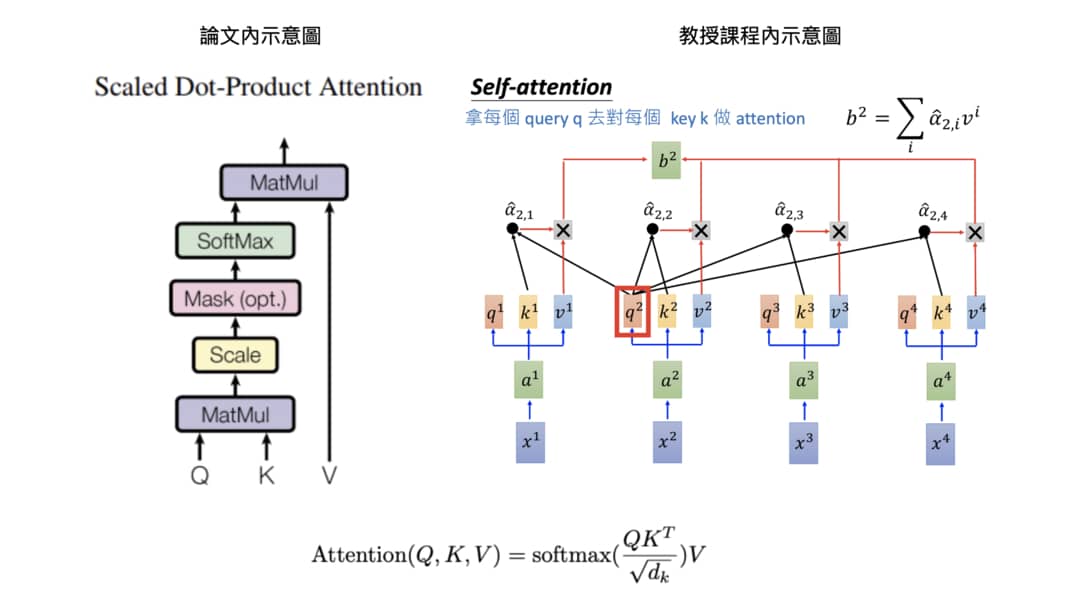
### Self-Attention layer
- 將 q 和 k 做點積得到 matmul_qk
- 將 matmul_qk 除以 scaling factor sqrt(dk)
- 有遮罩的話在丟入 softmax 前套用
- 通過 softmax 取得加總為 1 的注意權重
- 以該權重加權平均 v 作為輸出結果
- 回傳輸出結果以及注意權重
#### Scaled dot-product attention:一种注意函数
#### Mask
mask顾名思义就是掩码,在我们这里的意思大概就是对某些值进行掩盖,使其不产生效果。
需要说明的是,我们的Transformer模型里面涉及两种mask。分别是padding mask和look ahead mask(也称作sequence mask)。其中后者我们已经在decoder的self-attention里面见过啦!
其中,padding mask在所有的scaled dot-product attention里面都需要用到,而look ahead mask只有在decoder的self-attention里面用到。
- padding mask:遮住 <pad> token 不讓所有子詞關注
- look ahead mask:遮住 Decoder 未來生成的子詞不讓之前的子詞關注
#### Multi-head attention
mutli-head attention 的概念本身並不難,用比較正式的說法就是將 Q、K 以及 V 這三個張量先個別轉換到 d_model 維空間,再將其拆成多個比較低維的 depth 維度 N 次以後,將這些產生的小 q、小 k 以及小 v 分別丟入前面的注意函式得到 N 個結果。接著將這 N 個 heads 的結果串接起來,最後通過一個線性轉換就能得到 multi-head attention 的輸出。
<br/>
而為何要那麼「搞剛」把本來 d_model 維的空間投影到多個維度較小的子空間(subspace)以後才各自進行注意力機制呢?這是因為這給予模型更大的彈性,讓它可以同時關注不同位置的子詞在不同子空間下的 representation,而不只是本來 d_model 維度下的一個 representation。
#### Residual Connection
假设网络中某个层对输入x作用后的输出是F(x),那么增加residual connection之后,就变成了:F(x) + x
这个+x操作就是一个shortcut。
那么残差结构有什么好处呢?显而易见:因为增加了一项x,那么该层网络对x求偏导的时候,多了一个常数项1!所以在反向传播过程中,梯度连乘,也不会造成梯度消失!
#### Layer Normalization
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
那么什么是Layer normalization呢?:它也是归一化数据的一种方式,不过LN是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!
#### Positional Encoding
透過多層的自注意力層,Transformer 在處理序列時裡頭所有子詞都是�
Transformer:Seq2Seq 模型 + 自注意力機制

需积分: 0 82 浏览量
2023-02-10
10:44:23
上传
评论
收藏 5.92MB ZIP 举报
 Transformer-master.zip (30个子文件)
Transformer-master.zip (30个子文件)  Transformer-master cmn-eng
Transformer-master cmn-eng  training.txt 1.23MB
training.txt 1.23MB word2int_cn.json 57KB word2int_en.json 59KB preprocess en_code.txt 48KB dict.txt.big 8.19MB en_refine.txt 744KB tokenizer.py 1KB build_dataset.py 3KB en.txt 724KB build_dictionary.sh 239B cmn.txt 2.94MB en_vocab.txt 40KB dict.txt.small 1.48MB cn.txt 780KB int2word_en.json 66KB int2word_cn.json 65KB validation.txt 34KB testing.txt 183KB README.md 10KB code preprocess.py 2KB model.py 16KB data.py 3KB train.py 6KB __pycache__ preprocess.cpython-37.pyc 2KB test.cpython-37.pyc 2KB data.cpython-37.pyc 3KB model.cpython-37.pyc 12KB config.cpython-37.pyc 968B test.py 5KB config.py 1KB
word2int_cn.json 57KB word2int_en.json 59KB preprocess en_code.txt 48KB dict.txt.big 8.19MB en_refine.txt 744KB tokenizer.py 1KB build_dataset.py 3KB en.txt 724KB build_dictionary.sh 239B cmn.txt 2.94MB en_vocab.txt 40KB dict.txt.small 1.48MB cn.txt 780KB int2word_en.json 66KB int2word_cn.json 65KB validation.txt 34KB testing.txt 183KB README.md 10KB code preprocess.py 2KB model.py 16KB data.py 3KB train.py 6KB __pycache__ preprocess.cpython-37.pyc 2KB test.cpython-37.pyc 2KB data.cpython-37.pyc 3KB model.cpython-37.pyc 12KB config.cpython-37.pyc 968B test.py 5KB config.py 1KB资源评论













