




Machine Learning for Language
Processing
ACS 2015/16
Stephen Clark
L7: Word Embeddings

Neural Distributional Models
Continuous bag of words model, from Mikolov et al. 2013
Neural Distributional Models
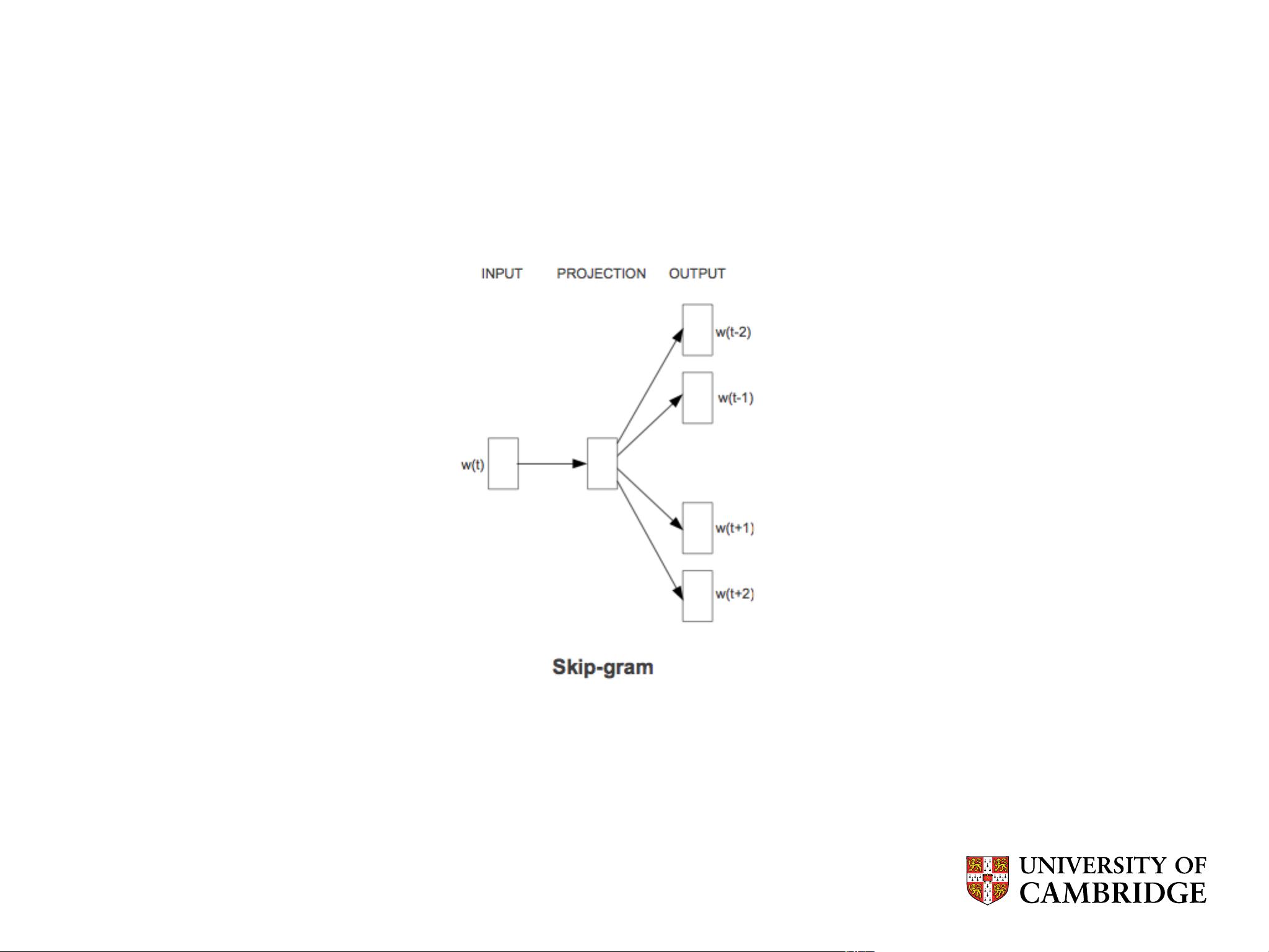
Skip-gram model; picture taken from Mikolov et al. 2013
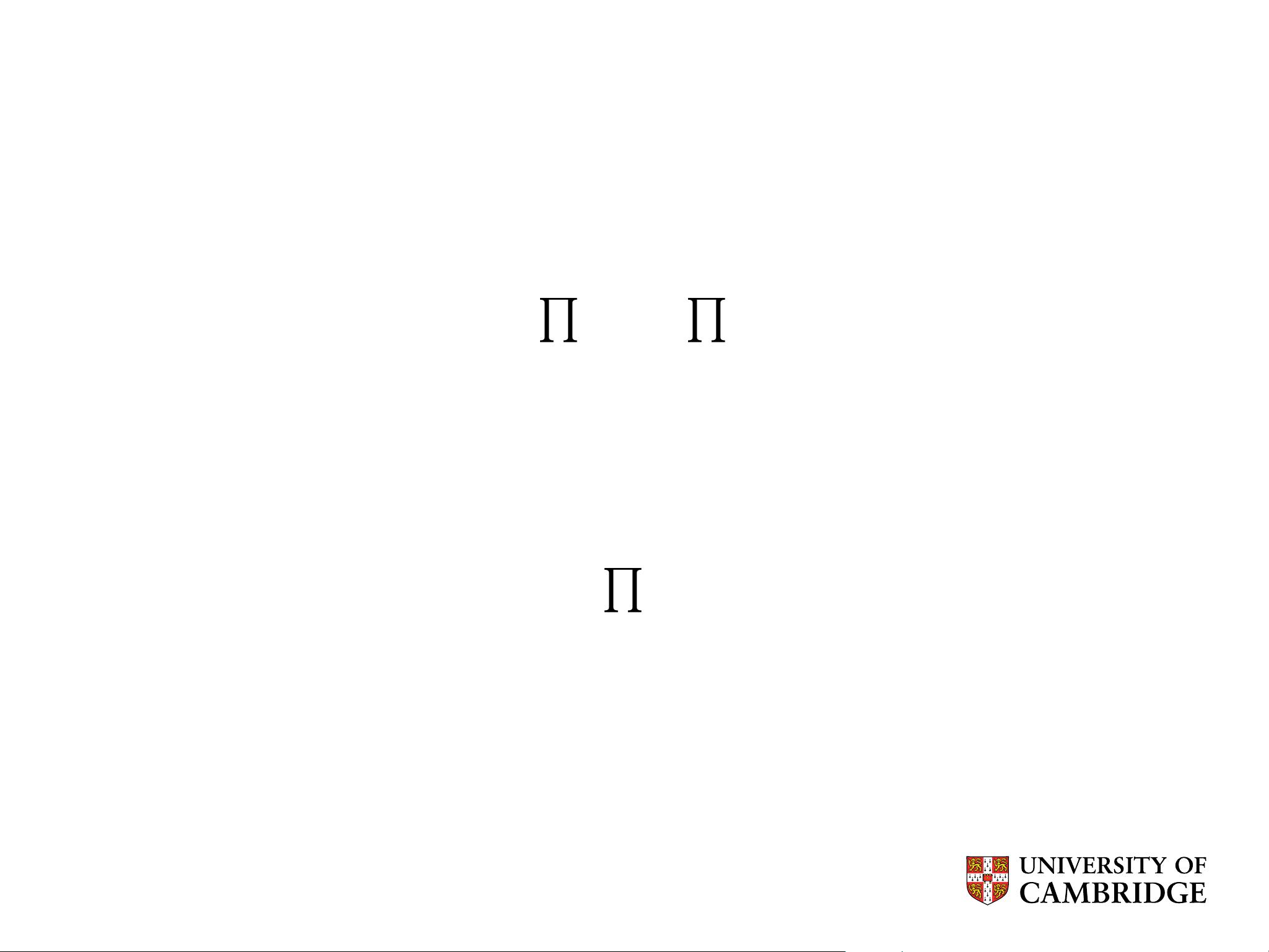
Skip-Gram “Language Modelling”
arg max
θ
�
w∈Text
�
c∈C(w)
p(c|w; θ)
where C(w) is the set of contexts for each word w
arg max
θ
�
(w,c)∈D
p(c|w; θ)
where D is the set of word, context pairs
Parameterisation of Skip-Gram
p(c|w, θ)=
e
v
c
·v
w
�
c
�
∈C
e
v
c
�
·v
w
where v
c
and v
w
∈ R
d
are ve ct or rep r ese ntations for c and w
and C is the set of all pos s i ble contexts













- 1
- 2
前往页