工业大数据架构.docx
版权申诉
186 浏览量
2022-06-22
01:12:12
上传
评论
收藏 157KB DOCX 举报

工业大数据架构
随着工业 4.0、工业互联网、中国制造 2025 等词的出现,掀起制造业建设的新一轮的浪潮。
近年来随着制造业信息化应用不断的完善,形成大量的数据积累下来,大家也都希望把这些
数据进行提炼出来,形成企业自己的数据资产,使之变为企业的生产力。如何来构建企业自
己的数据资源中心,以及数据最终应该如果应用?成为了众多企业思考的问题。小编一直从
事于制造业 IT 数据服务建设,运用自己所了解的知识给出一些建议,希望能给大家一些帮助。
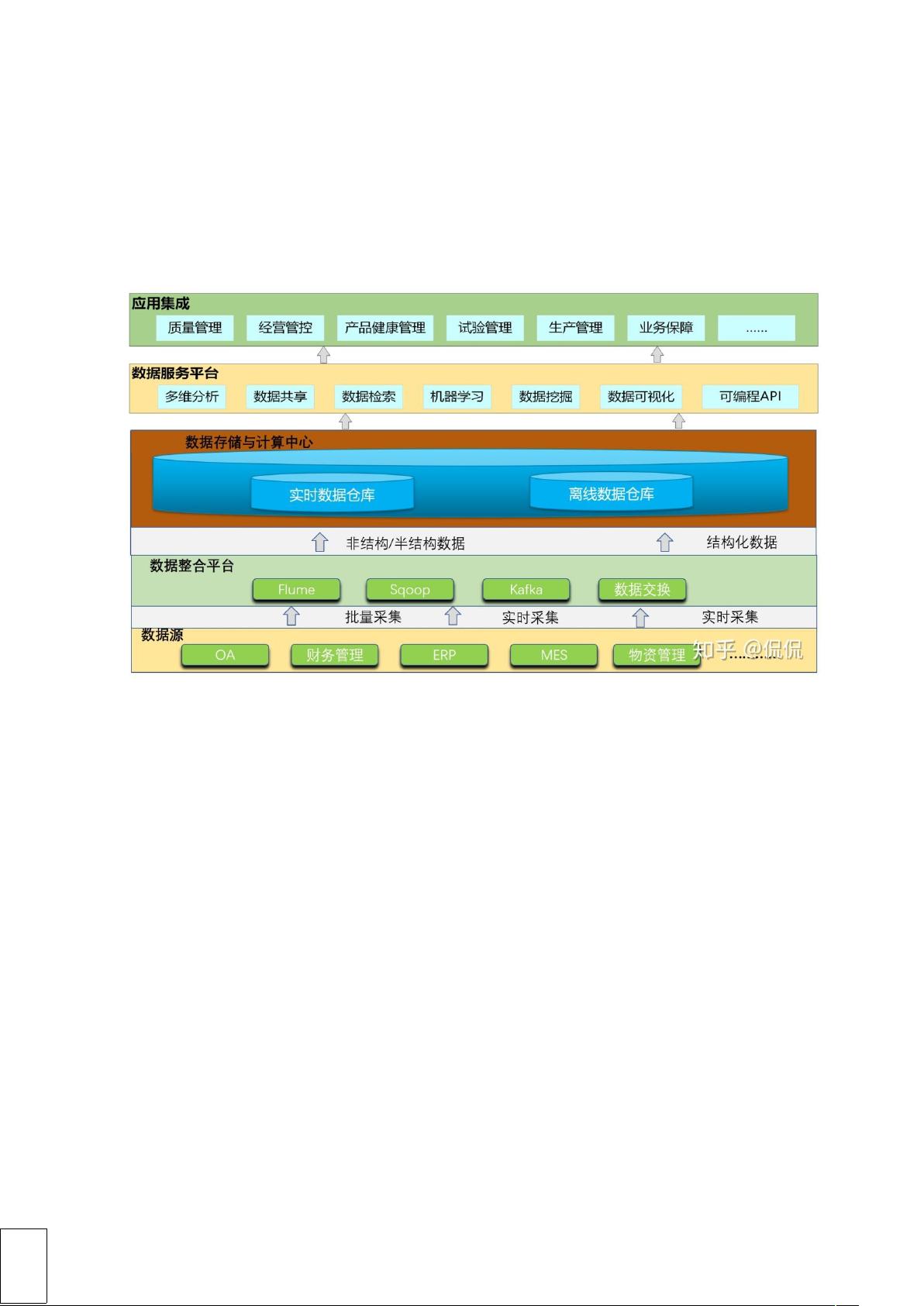
我们先来看一下如何来构建企业的大数据平台(数据资源中心),首先我们要想明白我数据资
源中心的架构,由那些模块平台来构成,我大概的整理出来一个架构图供大家参考:
我们以这张图为参考来具体的讲一下数据中心的构建:
1、数据源:也有是所有采集的数据的业务系统。根据业务统的主次,以及对接业务系统的
接口预算,咱们可以分期进行业务采集对接。也可以全部应用系统都进行对接。跟据企业现
实情况来进行判断。
2、数据的整合平台:也就是对采集好的数据进行清洗的平台,把采集到应用系统的数据进
行加工处理(ETL 过程)。针对不同的数据有不同的处理方式:
Flumen 实时日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时对
数据进行简单处理,并写到各种数据接收方。
Sqoop 是一个用来将和关系型数据库中的数据相互转移的工具,可以将一个关系型(例如 :
MySQL Oracle Postgres 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导
进到关系型数据库中。
Kafka 是一种高吞吐量的发布订阅消息系统,它可以处理消费者在网站中的所有动作流数
据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个
关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像
一样的数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka
的目的是通过的并行加载机制来统一线上和离线的消息处理,也是为了通过来提供实时的消
息。
通过这些工具把数据进行整理,输送上方的存储与计算平台。咱们也可以把这一过程理解为
在做家具时用的原材料加过的工程,一开始从各地方收集来的树,然后把树跟据不同的大
小,把他加工为木板和木柱,这样就成为做家具用的原材料了。这样也形成了对企业数据的
梳理整合成统一的标准,为以后企业的数据应用提供了可靠的原材料。
工
业
大
资源评论













