BERT实现情感分析.
需积分: 49 186 浏览量
2020-09-18
16:14:31
上传
评论 4
收藏 234KB DOCX 举报


使用 BERT 实现情感分析
在 CV 问题中,目前已经有了很多成熟的模型供大家使用,只需要结合特定
的业务场景修改结尾的全连接层或添加 softmax 层即可满足需求,也就是我们
常说的迁移学习。那么在 NLP 领域是否有这样泛化能力很强的模型呢,答案是
肯定的。
2018 年 底 , Google 推 出 了 一 个 打 破 11 项 NLP 任 务 的 模 型
BERT(Bidirectional Encoder Representation from Transformers),
该模型一经问世就火遍 AI 领域并受到了广大开发者的青睐,可以说是 NLP 领
域中具有里程碑意义的模型,目前 BERT 依旧是比赛中或者工业界首选的模型,
各大公司也均基于 BERT 进行了更多的升级与优化。
BERT 是一个预训练模型,该模型的训练阶段分为两个部分,预训练与微调,
预训练阶段 Google 已经处理好,如果要使用该模型,只需要针对特定场景进
行微调即可。在本章节中,我们会先介绍 BERT 的原理,再以一个实际的例子
来讲解如何微调。
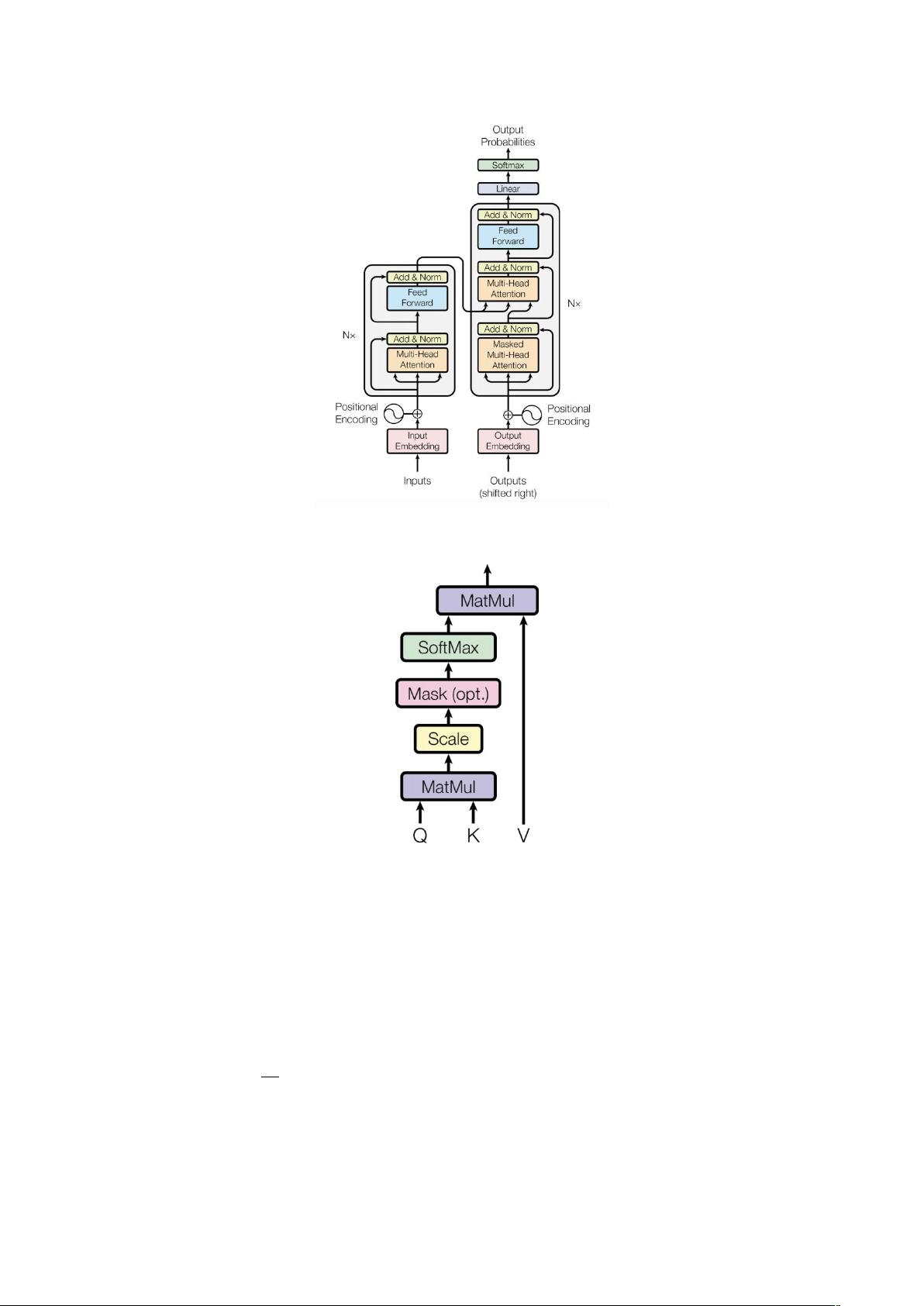
1. Transformer 模型
在 NLP 任务中,常用的特种提取器有 RNN 及其变体、CNN 搭配池化层、
Transformer 等,RNN 类型的提取器有一个最大的优点能捕捉长依赖信息,
但是其速度很慢,CNN 搭配池化层能有效获取一些重要的特征并忽略没有意义

剩余11页未读,继续阅读






评论0
最新资源