334 2019 年 4 月 6 日 第 14 章 深度强化学习
14.1 强化学习问题
强化学习广泛应用在很多领域,比如电子游戏、棋类游戏、迷宫类游戏、控
制系统、推荐等。这里我们介绍几个比较典型的强化学习例子。
14.1.1 典型例子
多臂赌博机问题 给定 K 个赌博机,拉动每个赌博机的拉杆(arm),赌博机会
按照一个事先设定的概率掉出一块钱或不掉钱。每个赌博机掉钱的概率不一样。
多臂赌博机问题(multi-armed bandit problem)是指,给定有限的机会次数 T ,
如何玩这些赌博机才能使得期望累积收益最大化。多臂赌博机问题在广告推荐、
也称为 K 臂赌博机问题(K-
armed bandit problem)。
投资组合等领域有着非常重要的应用。
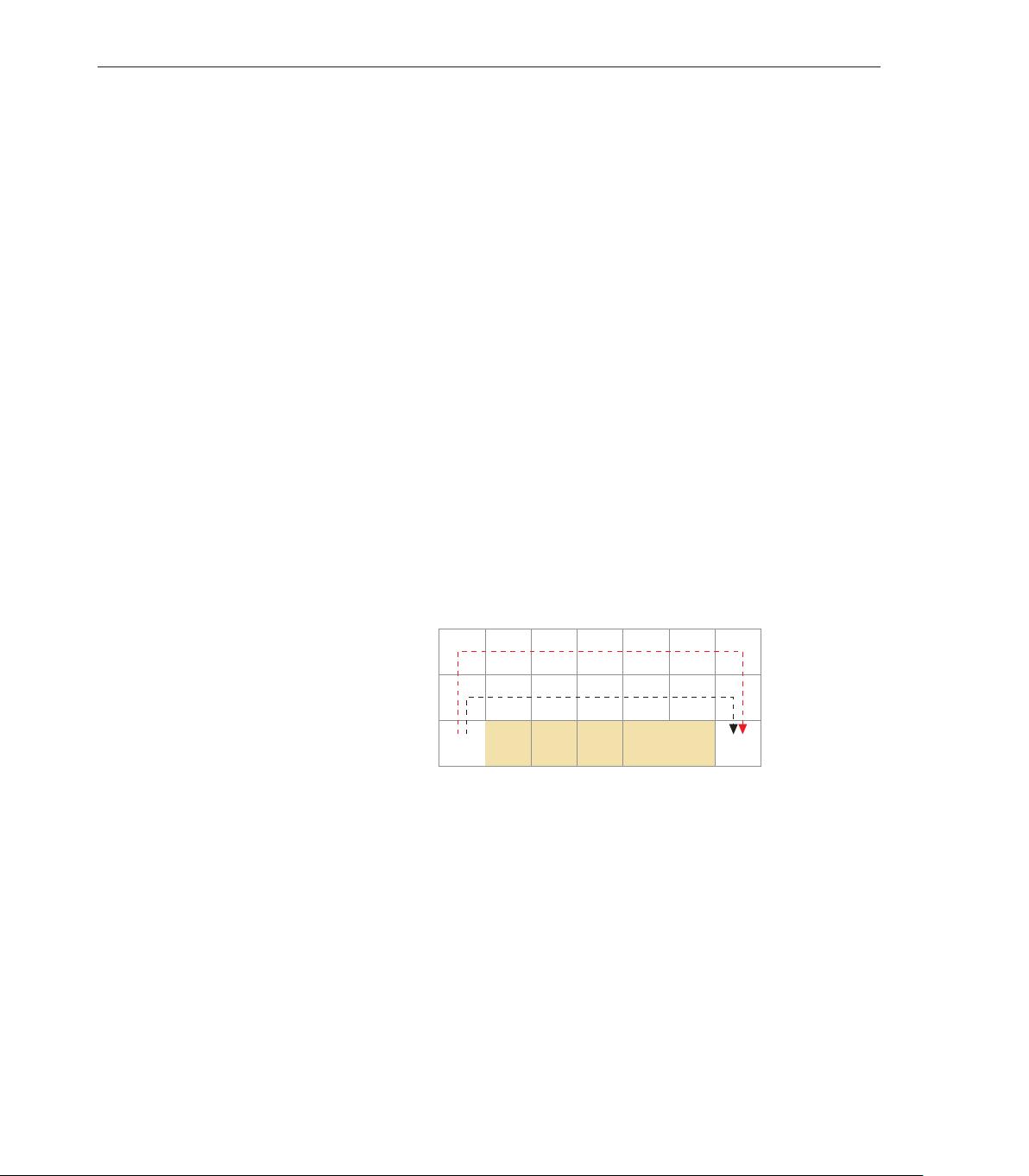
悬崖行走问题 在一个网格世界(grid world)中,每个格子表示一个状态。如14.1所
示的一个网格世界,每个状态为 (i, j), 1 ≤ i ≤ 7, 1 ≤ j ≤ 3,其中格子 (2, 1) 到
(6, 1) 是悬崖(cliff)。有一个醉汉,从左下角的开始位置 S,走到右下角的目标
位置 E。如果走到悬崖,醉汉会跌落悬崖并死去。醉汉可以选择行走的路线,即
在每个状态时,选择行走的方向:上下左右。动作空间 A = {↑, ↓, ←, →}。但每
走一步,都有一定的概率滑落到周围其他的格子。醉汉的目标是如何安全地到
达目标位置。
图 14.1 醉汉悬崖问题
14.1.2 强化学习定义
现在我们描述下强化学习的任务定义。在强化学习中,有两个可以进行交
互的对象:智能体和环境。
• 智能体(agent)可以感知外界环境的状态(state)和反馈的奖励(reward),
并进行学习和决策。
智能体的决策功能是指根据外界环境的状态来做出不同的动作(action),
而学习功能是指根据外界环境的奖励来调整策略。
邱锡鹏:《神经网络与深度学习》 https://nndl.github.io/






 陈游泳2023-07-26这本《chap-深度强化学习.pdf》用清晰简明的表达,使得复杂的概念易于理解,对于初学者也很友好。
陈游泳2023-07-26这本《chap-深度强化学习.pdf》用清晰简明的表达,使得复杂的概念易于理解,对于初学者也很友好。 VashtaNerada2023-07-26这本《chap-深度强化学习.pdf》循序渐进地讲解了深度强化学习的基础知识,适合初学者入门。
VashtaNerada2023-07-26这本《chap-深度强化学习.pdf》循序渐进地讲解了深度强化学习的基础知识,适合初学者入门。 daidaiyijiu2023-07-26这本《chap-深度强化学习.pdf》是非常值得一读的,详尽地介绍了深度强化学习的核心概念和应用案例。
daidaiyijiu2023-07-26这本《chap-深度强化学习.pdf》是非常值得一读的,详尽地介绍了深度强化学习的核心概念和应用案例。 书看不完了2023-07-26这本《chap-深度强化学习.pdf》讲解深度强化学习的角度独特,对于学习者来说十分实用。
书看不完了2023-07-26这本《chap-深度强化学习.pdf》讲解深度强化学习的角度独特,对于学习者来说十分实用。 学习呀三木2023-07-26这本《chap-深度强化学习.pdf》以通俗易懂的方式,给出了很多实践建议,对于想要实际运用深度强化学习的人来说非常实用。
学习呀三木2023-07-26这本《chap-深度强化学习.pdf》以通俗易懂的方式,给出了很多实践建议,对于想要实际运用深度强化学习的人来说非常实用。











