word2vec.pdf
需积分: 12 109 浏览量
2020-01-02
12:27:06
上传
评论
收藏 5.26MB PDF 举报


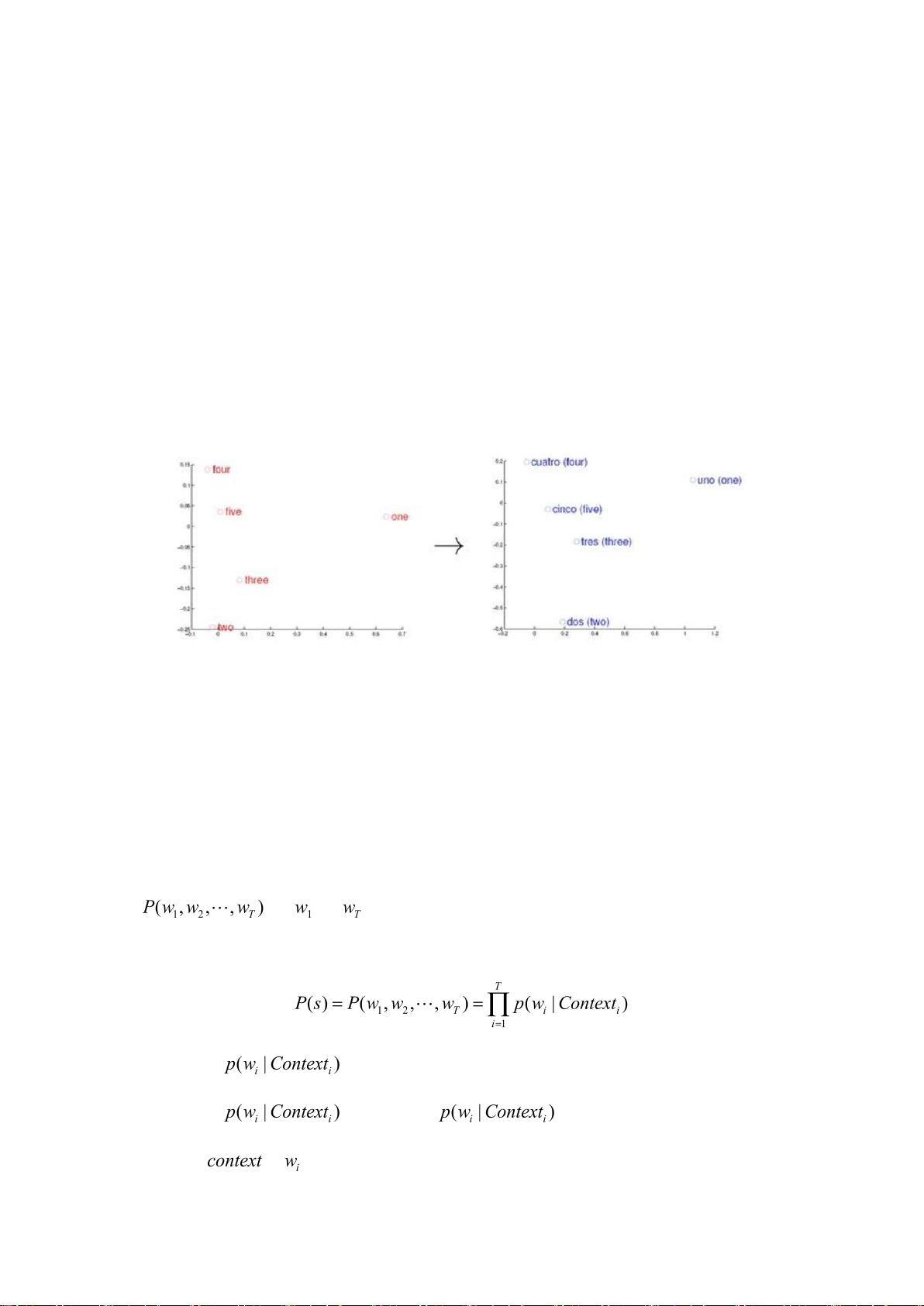
1 Word2vec
https://blog.csdn.net/itplus/article/details/37969979
在传统的 NLP 中,我们将单词视为离散符号,然后可以用 one-hot 向量表示。向量的维
度是整个词汇表中单词的数量。单词作为离散符号的问题在于,对于 one-hot 向量来说,没
有自然的相似性概念。因此,另一种方法是学习在向量本身中编码相似性。核心思想是一个
词的含义是由经常出现在其旁边的单词给出的。词向量是字符串的实值向量表示。我们为每
个单词建立一个密集的向量,选择它以便类似于类似上下文中出现的单词的向量。对于大多
数 NLP 任务而言,词向量被认为是一个很好的起点。它们允许深度学习在较小的数据集上
也是有效的,因为它们通常是深度学习体系的第一批输入,也是 NLP 中最流行的迁移学习
方式。在词向量中最流行的应该是 Word2vec,它是由谷歌开发的模型,另外一个是由斯坦
福大学开发的 GloVe。
1.2 词向量的意义
自然语言处理(NLP)相关任务中, 要将自然语言交给机器学习中的算法来处理,通
常需要首先将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东西
抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式了。
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词
转化成一个向量。
一种最简单的词向量方式是 one-hot representation,就是用一个很长的向量来表示一个
词,向量的长度为词典的大小,向量中只有一个 1,其它位置全为 0。1 的位置对应该词在
词典中的位置。这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也
就是给每个词都分配一个数字 ID。但这种词表示有两个缺点:(1)容易受维数灾难的困扰,
尤其是将其用于 Deep Learning 的一些算法时;(2)不能很好地刻画词与词之间的相似性。
另一种就是 Distributed Representation,其基本想法是直接用一个普通的向量表示一个
词,这种向量一般长成这个样子: [0.792, −0.177, −0.107, 0.109, −0.542, ... ],也就是普通
的向量表示形式。维度以 50 和 100 维常见。由于是用向量表示,而且用较好的训练算法得
到的词向量的向量一般是有空间上的意义的,也就是说, 将所有这些向量放在一起形成一



剩余23页未读,继续阅读
资源评论


纽约的自行车
- 粉丝: 76
- 资源: 17









最新资源
- AIS2024 valid
- 最入门的爬虫代码 python.docx
- 爬虫零基础入门-爬取天气预报.pdf
- 最通俗易懂的 MongoDB 非结构化文档存储数据库教程.zip
- 以mongodb为数据库的订单物流小项目.zip
- 腾讯云-mongodb数据库, 项目部署.zip
- 腾讯 APIJSON 的 MongoDB 数据库插件.zip
- 理解非关系型数据库和关系型数据库的区别.zip
- 操作简单的Mongodb网页web管理工具,基于Spring Boot2.0支持mongodb集群.zip
- tms-mongodb-web,提供访问mongodb数据的REST API和可灵活扩展的mongodb web 客户端.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


