2022年华数杯数学建模竞赛C题二等奖论文


1
所属类别
2022 年“华数杯”全国大学生数学建模竞赛
参赛编号
本科
CM2204721
插层熔喷非织造材料的性能控制研究
摘要
本文针对插层熔喷非织造材料的性能控制展开深入研究,通过典型相关、XGBoost、
皮尔逊 person 相关性、BP 神经网络等方法,使用 MATLAB、Python、SPSS、EXCEL 等软
件编程进行处理,得出了题目中结构变量、产品性能的变化规律;建立了工艺参数与结
构变量之间的预测模型;建立了皮尔逊相关性判定模型,分析了结构变量与产品性能以
及各自之间的关系等。最终结合研究成果得出了实际产品生产中能够使得过滤效率尽量
的高的同时力求过滤阻力尽量的小的工艺参数。
针对问题一,首先对附件一中数据进行预处理,先分析是否有不符合实际的极值数
据。然后对插层前后的产品结构变量、产品性能利用 SPSS26.0 对清洗后数据做描述性
统计。通过对比分析,插层后结构变量方面,厚度加厚,孔隙率和压缩回弹性降低等。
然后我们对插层率与结构变量与产品性能的变化进行单因素方差分析和皮尔逊相关性
分析。各个指标相关性存在显著差距,插层率与孔隙率变化和压缩回弹性率变化等因子
都具有显著的相关性,并且孔隙率变化还达到了高度相关,基本判断出插层率对结构变
量、产品性能变化规律有显著的影响。
针对问题二,预测类问题,首先对附件的数据进行筛选训练样本的预处理。基于表
1 与预处理结果构建了机器学习回归预测模型,根据结合附件中筛选后的工艺参数与结
构变量数据,分别在逻辑回归、决策树、随机森林和 XGBoost 进行不同的机器学习算法
上进行测试。经过与其他算法的对比与测试得到 XGBoost 预测为较好的预测方法。最后
通过 XGBoost 回归预测,给出了表 1 中各个工艺参数对应的结构变量的预测情况。
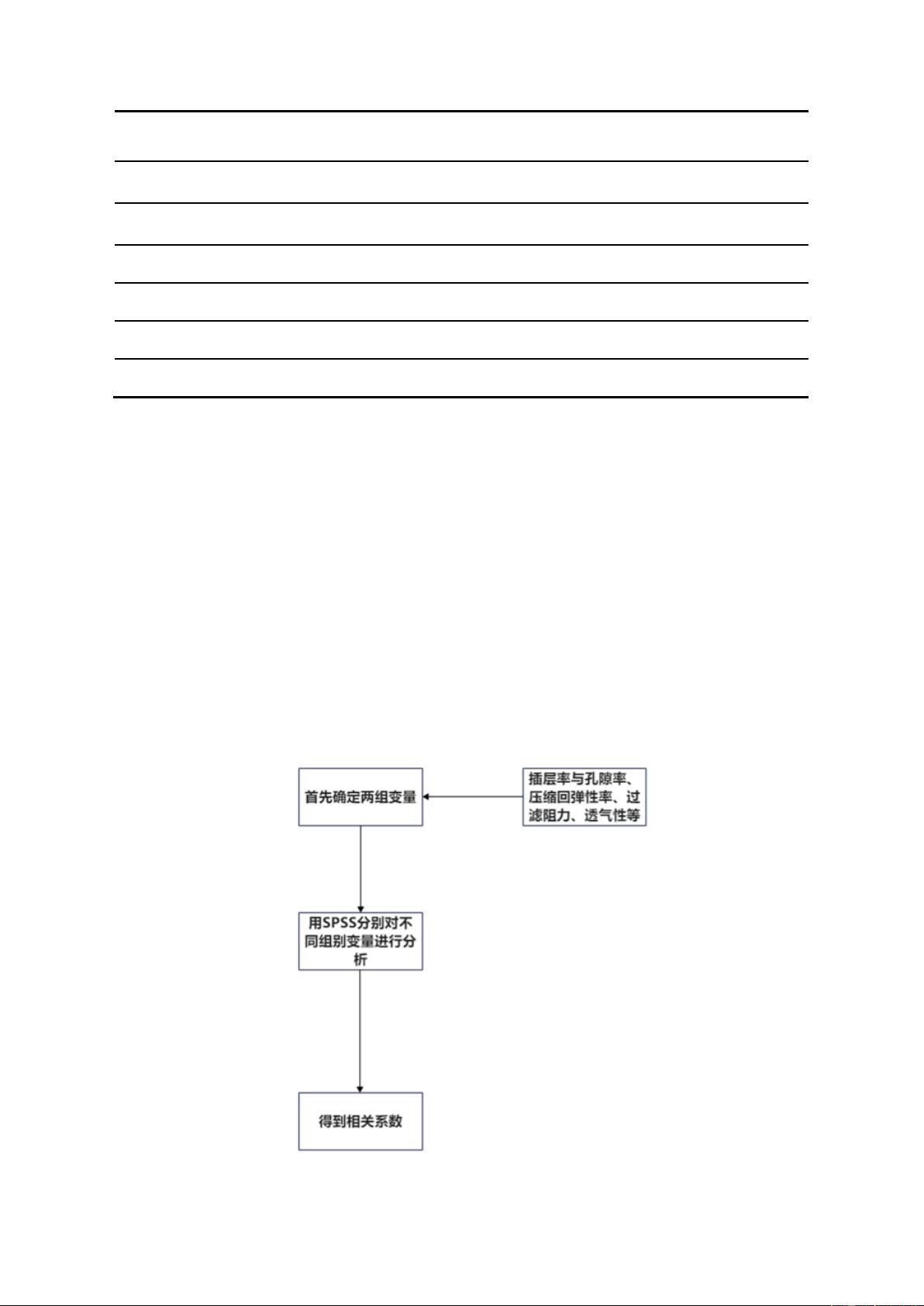
针对问题三,首先对结构变量与产品性能之间建立典型相关分析模型,发现两组多
元随机变量之间存在线性正相关关系,并通过 SPSS26.0 软件求解并进行分析。然后对
决定结构变量(厚度、孔隙率、压缩回弹性)和产品性能(过滤阻力、过滤效率、透气
性)之间分别进行皮尔逊相关性分析,发现不同结构变量之间和不同之间均存在具有显
著的相关性,其中厚度与孔隙率达到了高强度相关。然后对本题第三小问按照神经网络
深度学习所需环境对数据进行处理,把处理后的数据以数值矩阵的形式导入 MATLAB,以
“影响因子”作为输入,产品过滤效率作为输出进行训练,避免了拟合函数的选择,得
出相应工艺“黑匣子”函数,从而求出最优解:工艺参数接收距离为 19.1cm;热风速度
为 1386.4r/min 时,产品的过滤效率将会达到最高。
针对问题四,规划问题求解最优解。对实际产品生产进行进一步考虑,加入对实际
生产的各个指标实际情况考虑,同时过滤效率尽量的高,过滤阻力尽量的小,首先利用
熵权法求解过滤阻力与过滤效率之间的权重,然后根据权重大小构建两指标间的多目标
规划模型,以实际情况的限制作为限制条件,考虑到规划模型存在的欠缺,我们引入工
程优化的思想,利用粒子群算法对规划模型寻找全局最优解的过程进行优化,经过优化
后的模型更加高效与准确。经过灵敏度分析后发现,粒子群优化后模型稳定性较高。最
终对优化后的模型进行求解,从而得出研究结论。
关键词:皮尔逊 person 相关性 XGBoost BP 神经网络 多目标规划 粒子群优化


剩余23页未读,继续阅读
资源评论

 不会数分的屑2022-09-04第四问的偏差很大。。。
不会数分的屑2022-09-04第四问的偏差很大。。。












