

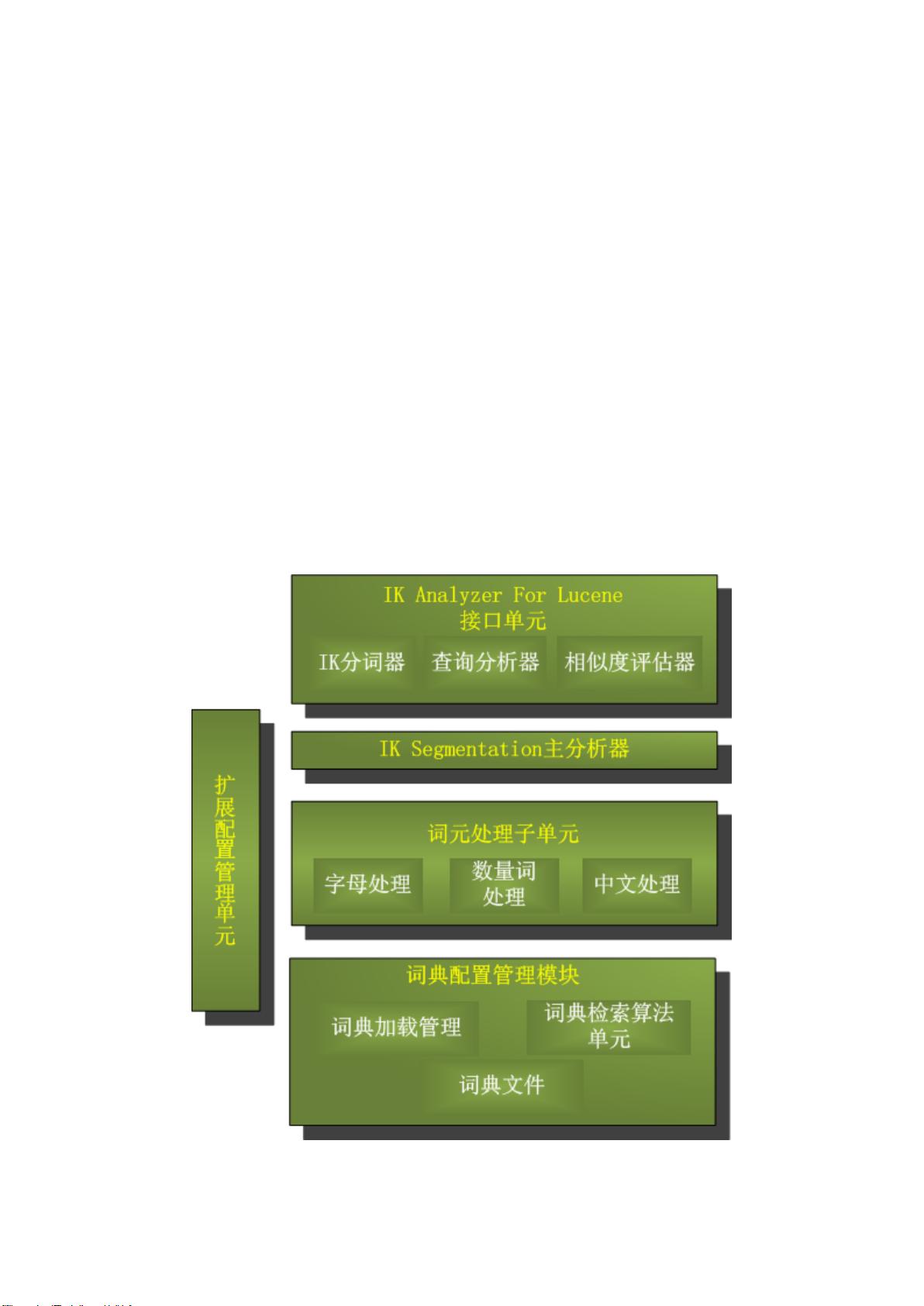
IKAnalyzer 中文分词器
V2012 使用手册
目录
1.IK Analyzer 2012 介绍 .................................................................................................. 2
2.使用指南 ........................................................................................................................ 5
3.词表扩展 ...................................................................................................................... 12
4.针对 solr 的分词器应用扩展 ...................................................................................... 15
5.关于作者 ...................................................................................................................... 16

剩余15页未读,继续阅读
资源评论













