



bbs.hadoopor.com --------hadoop 技术论坛
--------------------------------------------------------------------------------------------
创刊号 2010 年 1 月 - 1 -
www.hadoopor.com
2010 入门专刊


刊首语
刊首语
刊首语
刊首语
2010 年 1
月, 《
Hadoop 开发者》沐着 2010 年的第一缕春光诞生了。
正是有了 Doug Cutting 这样的大师级开源者, 正是有了无数个为 Hadoo p
贡献力量的开源者们的共同努力,才有了 Hadoop 自诞生时的倍受关注到现在
的倍受瞩目。 Hadoop 从单一应用发展到目前的 Hadoop Ecosystem ,自成一
格的技术体系, 叩开了信息爆炸时代的海量数据处理的大门, 开辟了海量数据 存
储与计算及其应用的新领地, 《
Hadoop 开发者》 正是在这样的背景下应运而
生。
Hadoop 技术交流群自创建起, 短短的几个月时间里就形成了 2 个超级大
群,
Hadoop 技术体系深蒙面向各行各业应用的开发者们的厚爱, 可以预见 Hado op
应用前景广阔。但时下稍显稚嫩,需要广大的爱好者共同尝试、探索,发掘应 用
的同时帮助改进。 《
Hadoop 开发者》 是 Hadoop 交流群的几位志愿者们自发 创
建的, 希望它的出现能为您的学习和探索铺路, 同时也期盼能分享您的 Hadoo p
之旅。在分享中, 《
hadoop 开发者》将与您一路同行,共同进步。
分享、自由、开放, 《
Hadoop 开发者》将秉承这一开源社区的血脉和传统
,
传承 “ 百家争鸣
”
,在思想交流和技术的切磋中促进 hadoop 社区的发展,期 待
Hadoop 这一尚待开垦的田野里 “ 百花齐放
”
。
最后,感谢《 Hadoop 开发者》编辑组所有同仁们,彼此素未蒙面的爱好 者
能聚到一起,为了一个共同的爱好策划这本杂志,这本身就是 Hadoop 魅力的
体现。当然,也要感谢大师 Doug Cutting 和 Hadoop 社区的开源者们,因为
有了您,这里才变得如此精彩!
《 Hadoop 开发者》编辑组 2010-1-27

目录
1 Hadoop 介绍
2 Hadoop 在国内应用情况
3 Hadoop 源代码 eclipse 编译教程
7 在 Windows 上安装 Hadoop 教程
1 3 在 Linux 上安装 Hadoop 教程
19 在 Windows 上使用 eclipse 编写 Hadoop 应用程序
24 在 Windows 中使用 Cygwin 安装 HBase
28 Nutch 与 Hadoop 的整合与部署
31 在 Windows eclipse 上单步调试 Hive 教程
38 Hive 应用介绍
42 Hive 执行计划解析
50 MapReduce 中的 Shuffle 和 Sort 分析
53 海量数据存储和计算平台的调试器研究
56 探讨 MapReduce 模型的改进
58 运行 eclipse 编译出的 Hadoop 框架
59 表关联在 MapReduce 上的实现
63 Hadoop 计算平台和 Hadoop 数据仓库的区别
bbs.hadoopor.com --------hadoop 技术论坛
--------------------------------------------------------------------------------------------
创刊号 2010 年 1 月 - 1 -
Hadoop
Hadoop
Hadoop
Hadoop 介绍
介绍
介绍
介绍
Hadoop 是 Apache 下的一个项目,由 HDFS 、 MapReduce 、 HBase 、 Hive 和 ZooKeeper
等成员组成。其中, HDFS 和 MapReduce 是两个最基础最重要的成员。
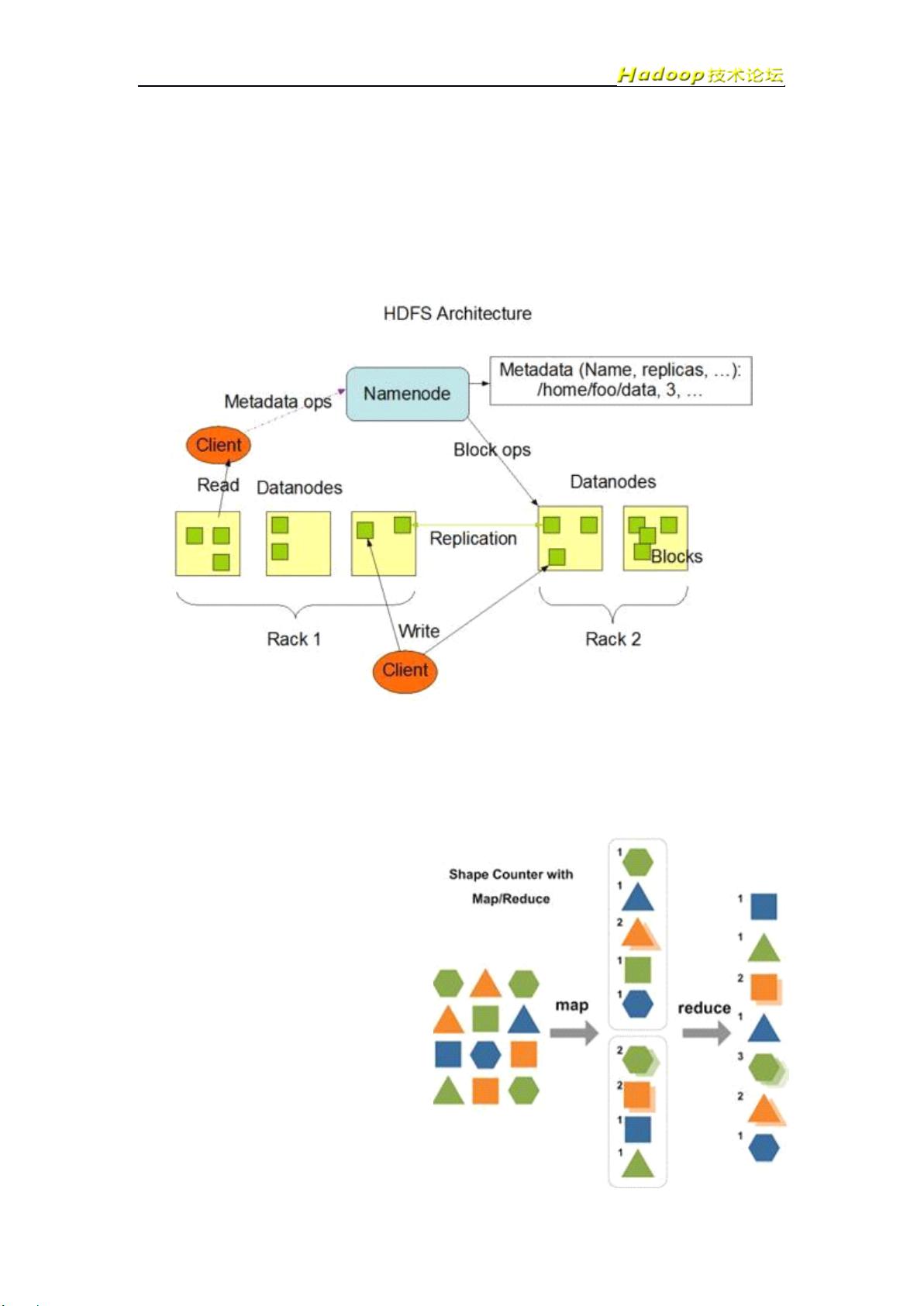
HDFS 是 Google GFS 的开源版本,一个高度容错的分布式文件系统,它能够提供高吞
吐量的数据访问,适合存储海量( PB 级)的大文件(通常超过 64M
) ,其原理如下图所示
:
采用 Master/Slave 结构。 NameNode 维护集群内的元数据,对外提供创建、打开、删除
和重命名文件或目录的功能。 DatanNode 存储数据, 并提负责处理数据的读写请求。 DataN ode
定期向 NameNode 上报心跳, NameNode 通过响应心跳来控制 DataNode 。
InfoWord 将 MapReduce 评为 2009 年十大新兴技术的冠军。 MapReduce 是大规模数据
( TB 级)计算的利器, Map 和 Reduce 是它的主要思想,来源于函数式编程语言,它的原
理如下图所示:
Map 负责将数据打散, Reduce
负责对数据进行聚集,用户只需要实
现 map 和 reduce 两个接口,即可完成
TB 级数据的计算,常见的应用包括:
日志分析和数据挖掘等数据分析应用。
另外,还可用于科学数据计算,如圆周
率 PI 的计算等。
Hadoop MapReduce 的实现也采用
了 Master/Slave 结构。 Master 叫做
JobTracker ,而 Slave 叫做 TaskTracker 。
用户提交的计算叫做 Job ,每一个
Job 会被划分成若干个 Tasks 。 JobTracker
负责 Job 和 Tasks 的调度,而 TaskTracker
负责执行 Tasks 。













- 1
- 2
- 3
- 4
- 5
- 6
前往页