machine leaning 谷歌课程
需积分: 5 194 浏览量
2022-10-09
10:25:10
上传
评论
收藏 1.75MB DOCX 举报


Restricted Information and Basic Personal Data
附录
历程位置: https://github.com/google/eng-edu/tree/main/ml/cc/exercises
简介
语法检测,人脸识别等通过大量数据来推断。
框架
什么是(监督)机器学习?简而言之,它是以下内容:
� ML 系统学习如何组合输入以对从未见过的数据产生有用的预测。
让我们探索基本的机器学习术语。
标签
标签是我们预测的东西——简单线性回归中的变量 y。标签可以是小麦的未来
价格、图片中显示的动物种类、音频剪辑的含义,或者任何东西。
特征
特征是一个输入变量——x 简单线性回归中的变量。一个简单的机器学习项目
可能使用单个特征,而更复杂的机器学习项目可能使用数百万个特征,具体如
下:
x1,x2,...xN
在垃圾邮件检测器示例中,功能可能包括以下内容:
� 电子邮件文本中的单词
� 寄件人地址
� 发送电子邮件的时间
� 电子邮件包含短语“一个奇怪的技巧”。


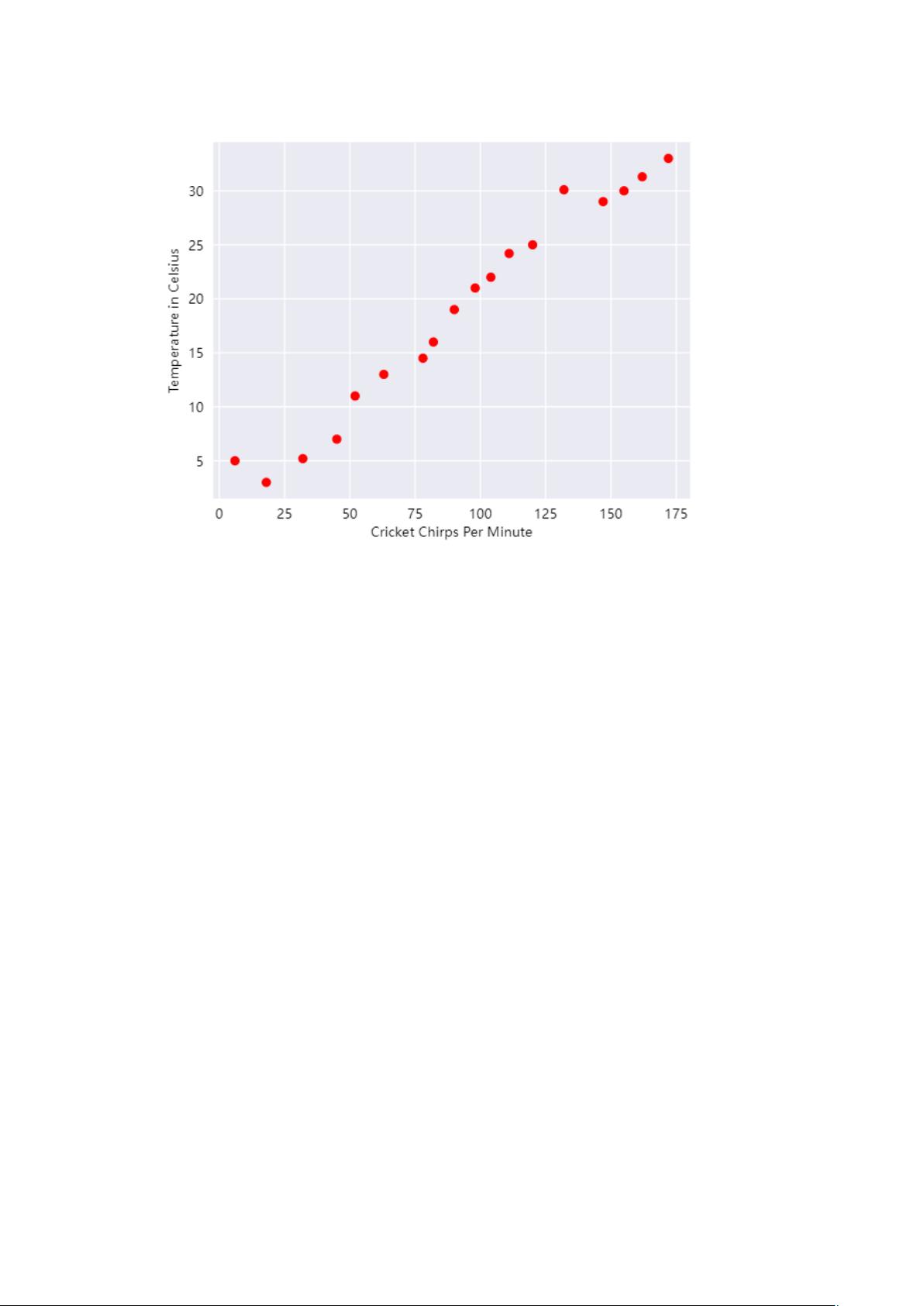
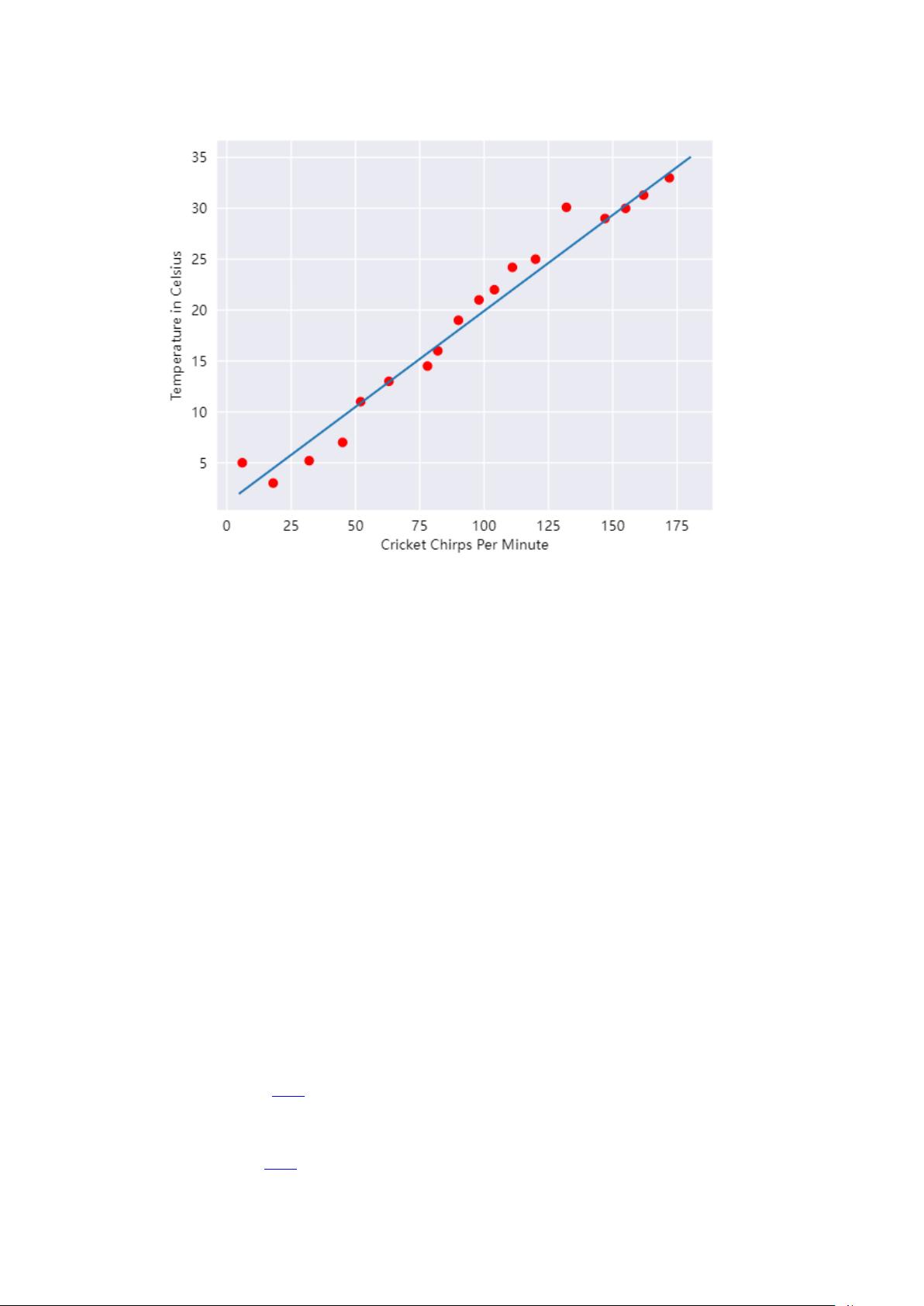
剩余60页未读,继续阅读
资源评论


弗泽智能
- 粉丝: 25
- 资源: 6









最新资源
- 人工智能ai相关教学课程快
- Suno的冲击-AI音乐来了-学习备用.pdf
- KIMI大模型浏览器插件
- b61fa64a08a02de0e0d49d53bb84c444.amr
- 分布式系统中Java后端开发技术及其应用实践.pdf
- 5ffd9193f6aec31bbf16030a46680dc7.avi
- DA14531-蓝牙传感器连接传输数据固件
- 极限存在准则与两个重要极限
- logisim实验MIPS运算器(ALU)设计(内含4位先行进位74182、四位快速加法器、32位快速加法器)-Educoder_logisim里面连线,实现4位先行进位74182和4位快速加法器-C
- 高等数学第一章第二节数列的极限
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


