用 Hadoop 进行分布式并行编程


用 Hadoop 进行分布式并行编程第 1 部分
Hadoop 简介
Hadoop 是一个开源的可运行于大规模集群上的分布式并行编程框架,由
于分布式存储对于分布式编程来说是必不可少的,这个框架中还包含了一个分布
式文件系统 HDFS( Hadoop Distributed File System )。也许到目前为止,
Hadoop 还不是那么广为人知,其最新的版本号也仅仅是 0.16,距离 1.0 似
乎都还有很长的一段距离,但提及 Hadoop 一脉相承的另外两个开源项目 Nu
tch 和 Lucene ( 三者的创始人都是 Doug Cutting ),那绝对是大名鼎鼎。L
ucene 是一个用 Java 开发的开源高性能全文检索工具包,它不是一个完整的
应用程序,而是一套简单易用的 API 。在全世界范围内,已有无数的软件系统,
Web 网站基于 Lucene 实现了全文检索功能,后来 Doug Cutting 又开创了
第一个开源的 Web 搜索引擎(http://www.nutch.org) Nutch, 它在 Luce
ne 的基础上增加了网络爬虫和一些和 Web 相关的功能,一些解析各类文档格
式的插件等,此外,Nutch 中还包含了一个分布式文件系统用于存储数据。从
Nutch 0.8.0 版本之后,Doug Cutting 把 Nutch 中的分布式文件系统以及
实现 MapReduce 算法的代码独立出来形成了一个新的开源项 Hadoop。Nut
ch 也演化为基于 Lucene 全文检索以及 Hadoop 分布式计算平台的一个开
源搜索引擎。
基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序,并将
其运行于由成百上千个结点组成的大规模计算机集群上。从目前的情况来看,H
adoop 注定会有一个辉煌的未来:"云计算"是目前灸手可热的技术名词,全球
各大 IT 公司都在投资和推广这种新一代的计算模式,而 Hadoop 又被其中几
家主要的公司用作其"云计算"环境中的重要基础软件,如:雅虎正在借助 Hado
op 开源平台的力量对抗 Google, 除了资助 Hadoop 开发团队外,还在开发
基于 Hadoop 的开源项目 Pig, 这是一个专注于海量数据集分析的分布式计
算程序。Amazon 公司基于 Hadoop 推出了 Amazon S3 ( Amazon Sim
ple Storage Service ),提供可靠,快速,可扩展的网络存储服务,以及一个
商用的云计算平台 Amazon EC2 ( Amazon Elastic Compute Cloud )。
在 IBM 公司的云计算项目--"蓝云计划"中,Hadoop 也是其中重要的基础软
件。Google 正在跟 IBM 合作,共同推广基于 Hadoop 的云计算。
迎接编程方式的变革
在摩尔定律的作用下,以前程序员根本不用考虑计算机的性能会跟不上软件
的发展,因为约每隔 18 个月,CPU 的主频就会增加一倍,性能也将提升一倍,
软件根本不用做任何改变,就可以享受免费的性能提升。然而,由于晶体管电路
已经逐渐接近其物理上的性能极限,摩尔定律在 2005 年左右开始失效了,人
类再也不能期待单个 CPU 的速度每隔 18 个月就翻一倍,为我们提供越来越
快的计算性能。Intel, AMD, IBM 等芯片厂商开始从多核这个角度来挖掘 CP
U 的性能潜力,多核时代以及互联网时代的到来,将使软件编程方式发生重大
变革,基于多核的多线程并发编程以及基于大规模计算机集群的分布式并行编程
是将来软件性能提升的主要途径。

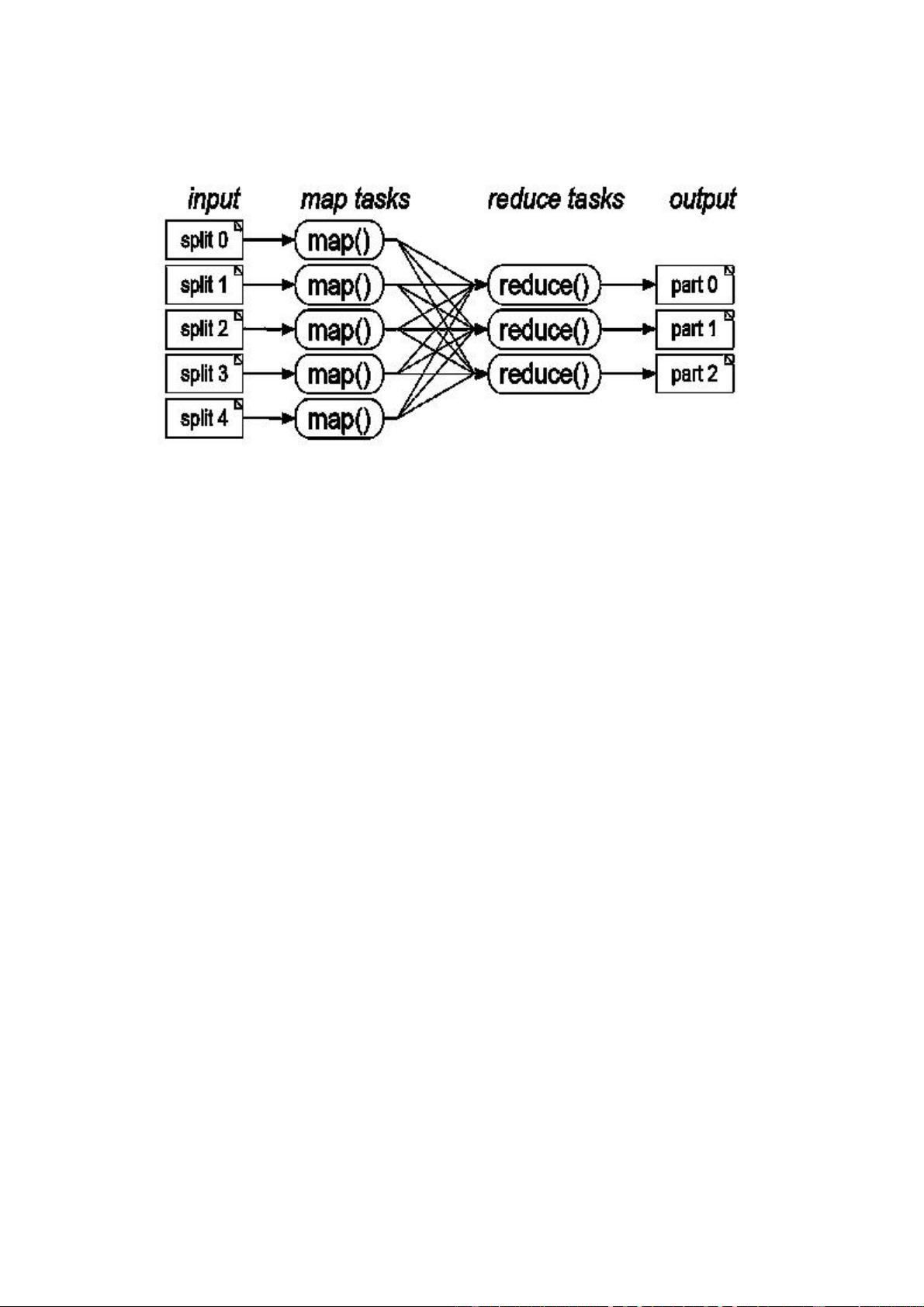

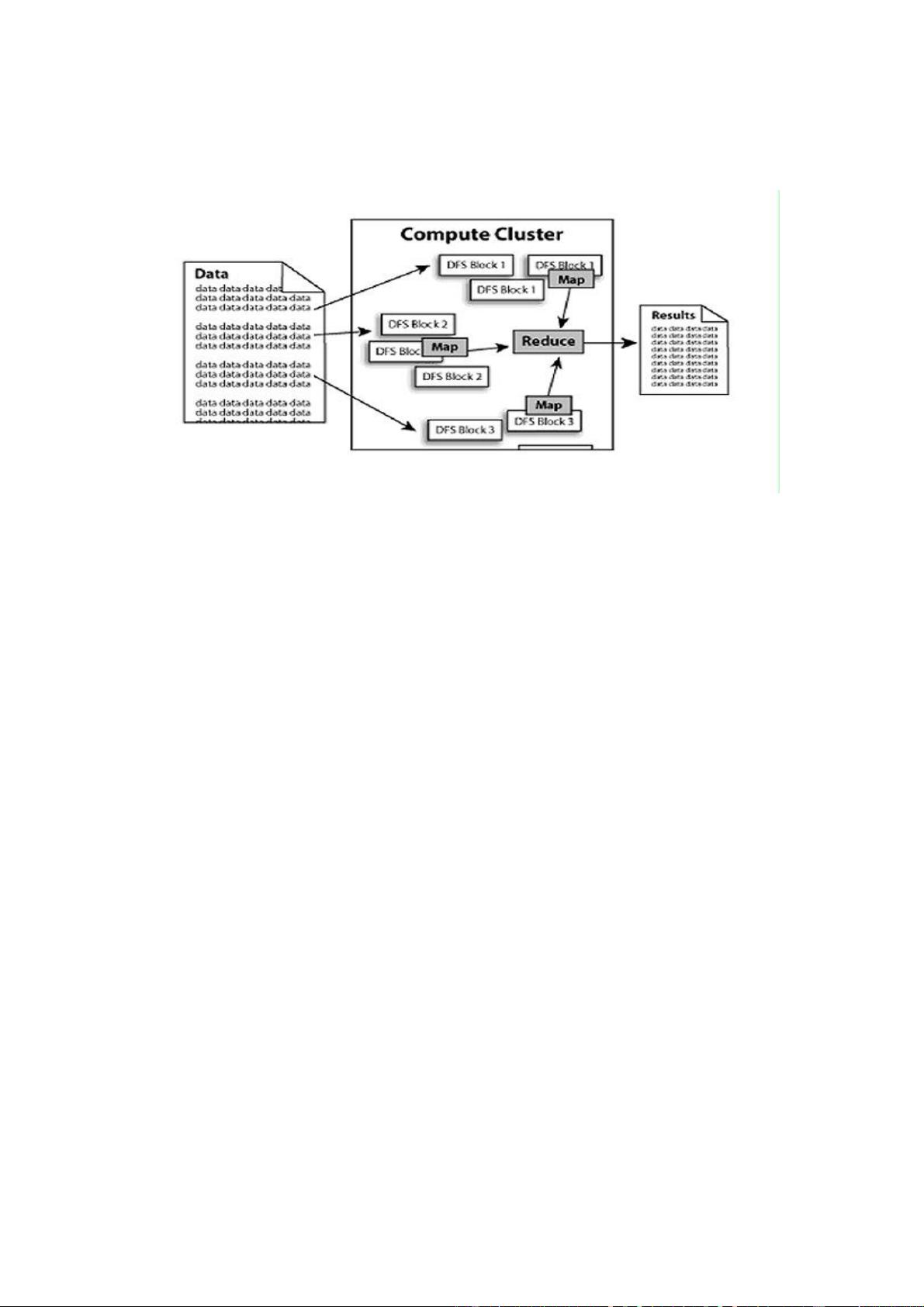
剩余38页未读,继续阅读
资源评论

 daishiju2012-06-26不错哦,入门级的部署和程序开发过程描述
daishiju2012-06-26不错哦,入门级的部署和程序开发过程描述

fengyingcong1991
- 粉丝: 21
- 资源: 51









最新资源
- 《CKA/CKAD应试指南/从docker到kubernetes 完全攻略》学习笔记 第1章docker基础(1.1-1.4)
- 基于python实现的水下压缩空气储能互补系统建模仿真与经济效益分析+源代码+论文
- 华中科技大学-自然语言处理实验,Bi-LSTM+CRF的中文分词框架,并且利用基于深度学习的方法进行中文命名实体识别++源码报告
- 基于动态罚函数的铁路车流分配与径路优化模型python源码
- 鱼群算法求解组环问题python源码+文档说明
- 基于决策优化的多波束测深测线规划模型MATLAB代码
- 课程设计-基于python实现的多目标优化算法求解带时间窗的车辆路径规划问题+源代码+文档说明+界面截图+pptx
- 基于通信信号与通信系统的MATLAB仿真源码-课程设计
- 嵌入式-信号机制(概念,发送,定时,捕捉,SIGCHLD 信号实现回收子进程)
- c语言管理系统大一大二笔记
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


