基于hadoop的词频统计.docx
需积分: 50 71 浏览量
2020-06-18
22:53:20
上传
评论 13
收藏 3.85MB DOCX 举报


摘要
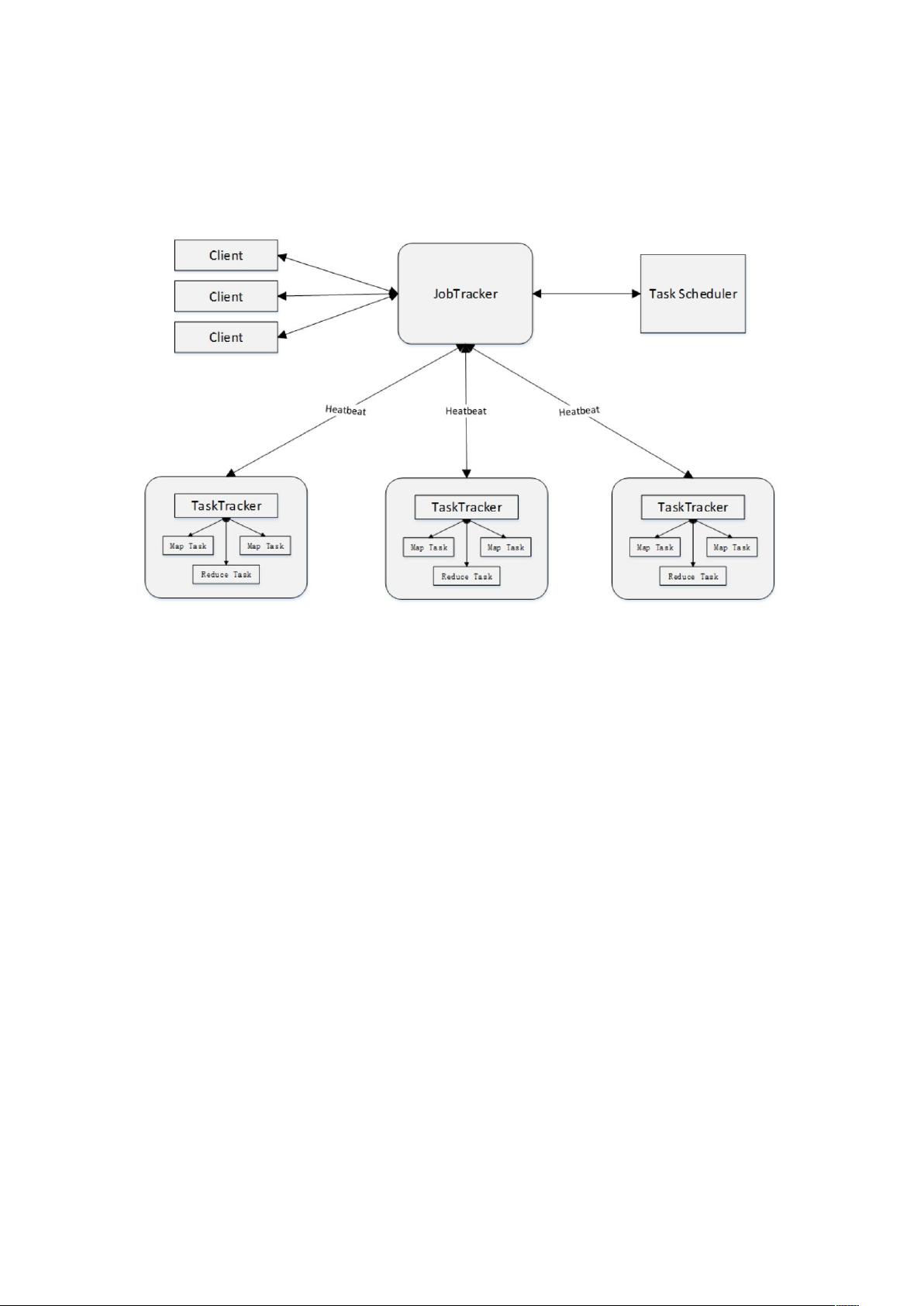
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在
不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行
高速运算和存储。Hadoop 实现了一个分布式文件系统,简称 HDFS。HDFS
有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量
来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS 放宽了
POSIX 的要求,可以以流的形式访问文件系统中的数据。Hadoop 的框架最核
心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而
MapReduce 则为海量的数据提供了计算。
关键词:hadoop,MapReduce,云计算,hdfs
I



剩余31页未读,继续阅读
资源评论













