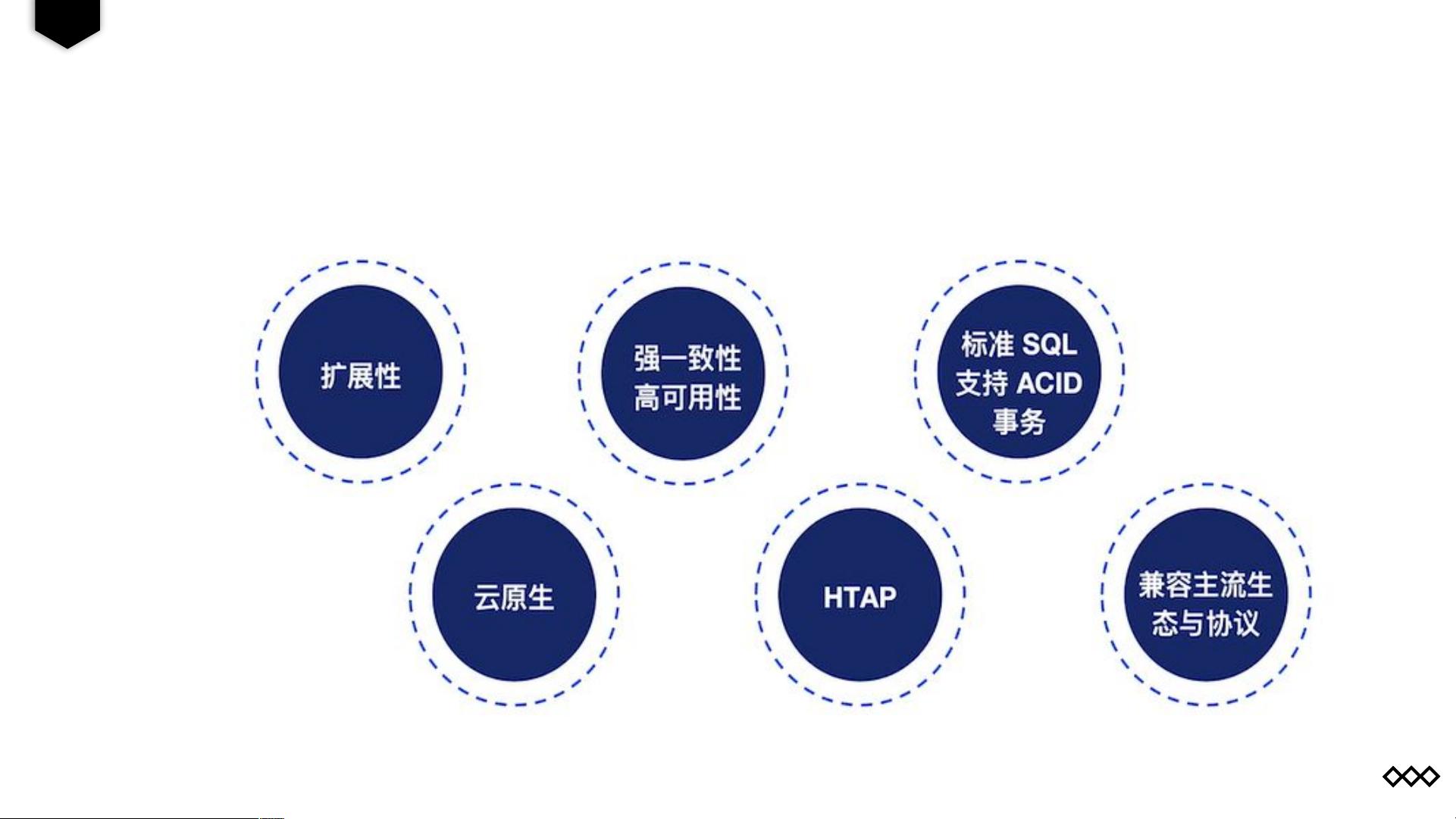
TiDB(TiKV + MySQL)是一款开源的分布式NewSQL数据库,设计目标是支持在线事务处理(OLTP)和在线分析处理(OLAP)混合的工作负载,具有水平扩展性和强一致性的分布式事务能力。以下是关于TiDB数据库基础培训资料的详细说明:
### 1. TiDB 体系架构
TiDB 的体系架构主要由以下组件构成:
- PD (Placement Driver):负责整个集群的元数据管理、调度和负载均衡。
- TiKV:分布式事务存储引擎,基于 RocksDB 实现,并采用了 Raft 一致性算法。
- TiDB Server:SQL 引擎,负责解析 SQL 请求,与 PD 和 TiKV 交互执行查询。
TiDB 采用计算与存储分离的设计,这使得它可以灵活地扩展计算和存储资源。在架构上,TiDB 是一个无中心、分布式的数据库,数据可以在多个节点间自动分片和复制,以实现高可用性和水平扩展性。
### 2. 集群管理
TiDB 集群管理涉及以下几个关键点:
- 部署:可以通过 TiUP 工具进行一键部署,快速搭建 TiDB 集群。
- 监控:通过 Prometheus 和 Grafana 进行集群状态监控,包括 CPU 使用率、内存消耗、网络流量等指标。
- 扩缩容:可以在线添加或移除节点,无需停机服务。
- 负载均衡:PD 负责数据的调度和分配,确保数据均匀分布在整个集群中。
### 3. 备份恢复
TiDB 支持多种备份策略,包括全量备份和增量备份。常见的备份工具如 TiDB Binlog 和 TiDB Lightning 可用于数据导入导出。备份恢复过程保证了数据的安全性和一致性,即使在集群故障后也能迅速恢复服务。
### 4. 数据迁移
数据迁移通常涉及到将数据从其他数据库系统迁移到 TiDB 或在 TiDB 集群内部迁移。TiDB Lightning 和 TiDB Binlog 可用于快速迁移大量数据。此外,使用 PD 的数据迁移功能,可以在不影响业务的情况下进行数据的平滑迁移。
### 5. 数据同步与复制
TiDB 实现了基于分布式事务的强一致性的数据复制。每个 TiKV 节点都有多个副本,通过 Raft 协议保持数据的一致性。此外,TiDB Binlog 提供实时的数据流服务,可以将数据变更实时同步到其他系统,如大数据分析平台,实现 HTAP(Hybrid Transactional/Analytical Processing)。
在TiDB 中,LSM-tree 结构被用于存储引擎,它优化了写入性能,牺牲了一定的读取效率。多副本机制保证了数据的高可用性,通过选举确定主节点来保证一致性。随着数据节点的增加,TiDB 可以轻松扩展存储和计算能力,满足不断增长的业务需求。
TiDB 作为一款分布式数据库,其强大的体系架构和集群管理能力,以及对备份恢复、数据迁移和同步复制的良好支持,使其成为应对大规模并发交易和复杂分析场景的理想选择。学习和掌握 TiDB 的基础知识,对于提升数据库管理和运维能力至关重要。

















评论0