先上Demo,我们根据这个Demo一步一步的跟进代码,看看代码里面发生了什么?
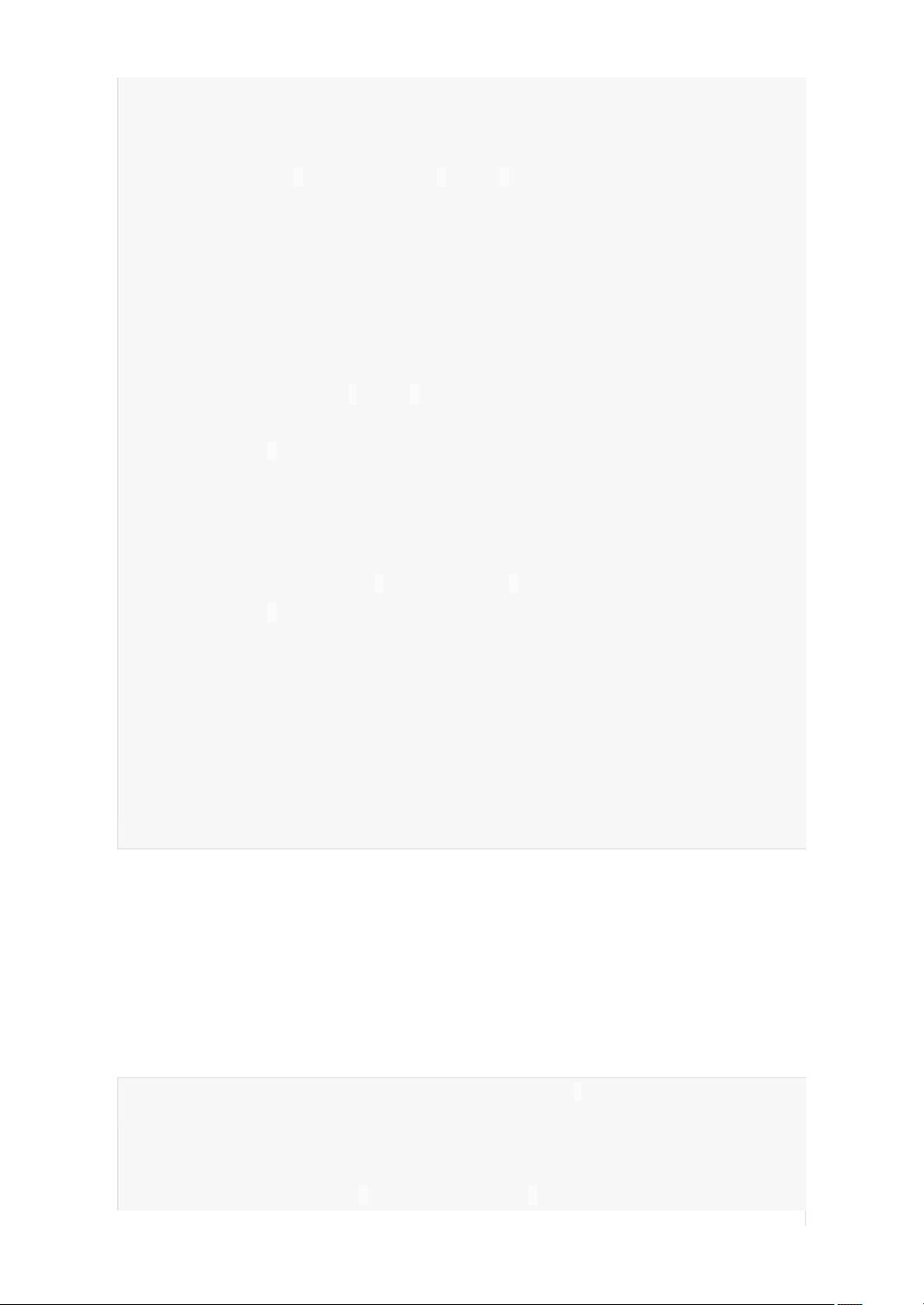
1 //一下代码共有8个rdd,4个Stage:ShuffleMapStage0,ShuffleMapStage1,Shuffl
eMapStage2,ResultStage3
2 objectUserViewCount{
3 defmain(args:Array[String]):Unit={
4 valconf=newSparkConf()
5 conf.setAppName("UserViewCount").setMaster("local[2]")
6 valsc=newSparkContext(conf)
7 valpath="C:\empcl\data\1.txt"
8
9 vallineRDD=sc.textFile(path)//rdd1
10 valdateRDD=lineRDD.map(line=>{//rdd2
11 valdate=line.split(" ")(0)
12 (date,1)
13 })
14
15 valreduceRDD=dateRDD.reduceByKey(_+_)//rdd3
16 valaddOneRDD=reduceRDD.map(x=>(x._1,x._2+1))//rdd4
17 valgroupRDD=addOneRDD.groupByKey()//rdd5
18 .map(x=>{//rdd6
19 valkey=x._1
20 (key,1)
21 })
22 valresRDD=groupRDD.reduceByKey(_+_)//rdd7
23 resRDD
24 .map(x=>x)//rdd8
25 .collect().foreach(println)
26 sc.stop()
27 }
28 }
当我们使用action算子collect的时候,就触发了job的执行。我们跟进下代码看看。
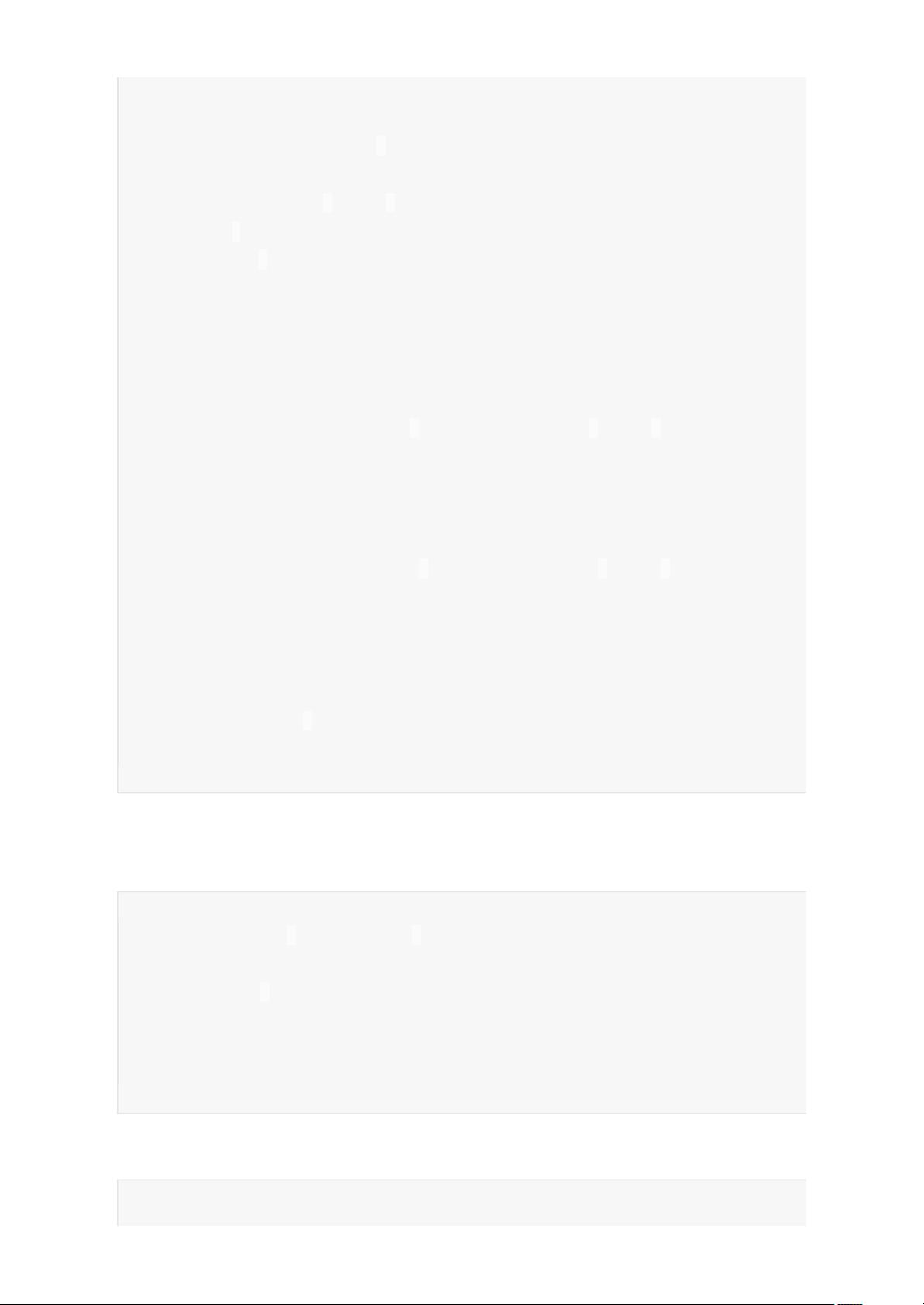
1 defcollect():Array[T]=withScope{
2 valresults=sc.runJob(this,(iter:Iterator[T])=>iter.toArray)
3 Array.concat(results:_*)
4 }
5 //RunajobonallpartitionsinanRDDandreturntheresultsinanarr
ay.
6 defrunJob[T,U:ClassTag](rdd:RDD[T],func:Iterator[T]=>U):Array[U]
={