3. url 通常定义目标地址的变量名,response 通常定义服务器返回响应的变量名,content
通常定义爬到的网络源码
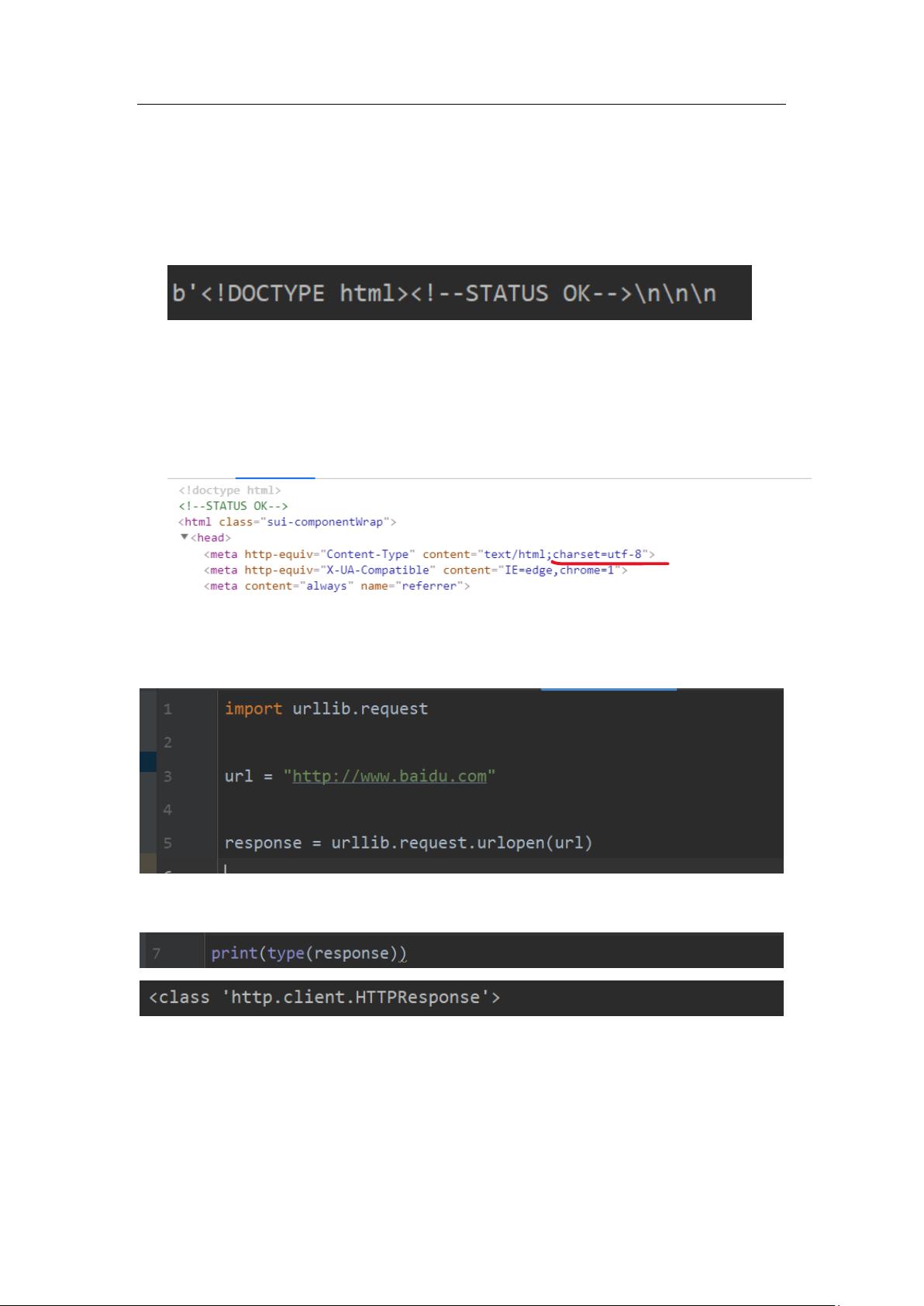
4. 在不进行解码的时候,read()方法返回的是 2 进制数据(2 进制数据标记源码首行有 b’)
5. 在对二进制进行解码时,可以使用.decode(“解码格式”) 进行解码,虽然说目前网络绝大
部分网络都采用了 utf -8 编码,但也有小部分别的,可以通过网页 F12 快捷键找到以下
代码可知道该网站使用了什么样的编码语言,从而对应解码。
urllib 的一个属性和六个方法
➢ 一个属性 :响应的类型:HTTPResponse
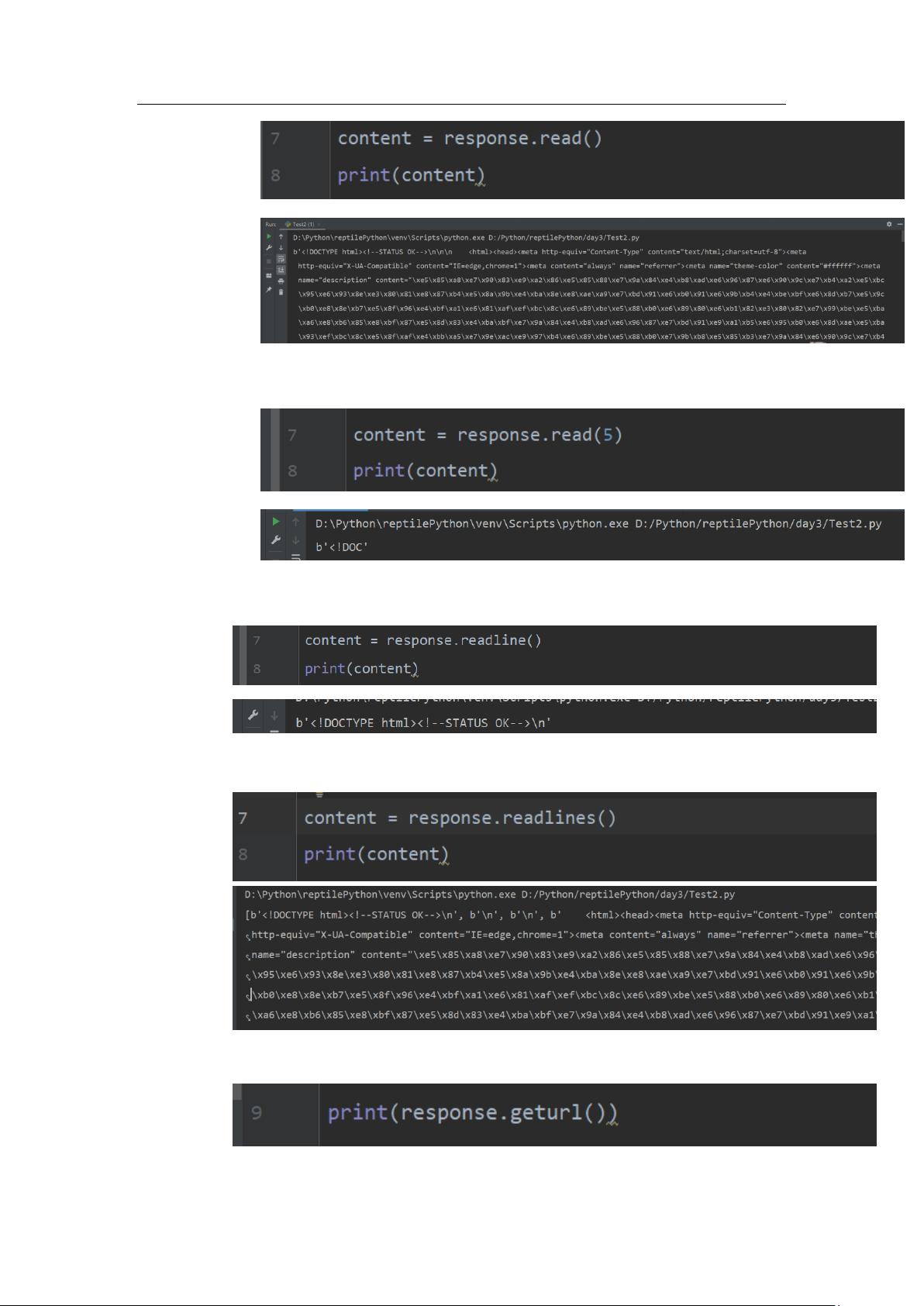
➢ 六个方法:read()/read(n), readline(),readlines(),geturl(),getcode(),getheaders()
1. read() / read(n): 两个重载的方法
1.1 read():一个字节一个字节的爬取,直到末尾结束

















评论0