Google MapReduce中文版
需积分: 10 64 浏览量
2018-08-17
22:46:34
上传
评论
收藏 186KB DOCX 举报


Google MapReduce 中文版
译者: alex
摘要
MapReduce 是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。
用户首先创建一个 Map 函数处理一个基于 key/value pair 的数据集合,输出中间的基于
key/value pair 的数据集合;然后再创建一个 Reduce 函数用来合并所有的具有相同中间
key 值的中间 value 值。现实世界中有很多满足上述处理模型的例子, 本论文将详细描述
这个模型。
MapReduce 架构的程序能够在大量的普通配置的计算机上实现并行化处理。这个系统在
运行时只关心:如何分割输入数据,在大量计算机组成的 集群上的调度,集群中计算机的
错误处理,管理集群中计算机之间必要的通信。采用 MapReduce 架构可以使那些没有并
行计算和分布式处理系统开发经验的 程序员有效利用分布式系统的丰富资源。
我们的 MapReduce 实现运行在规模可以灵活调整的由普通机器组成的集群上:一个典型
的 MapReduce 计算往往由几千台机器组成、处理 以 TB 计算的数据。程序员发现这个系
统非常好用:已经实现了数以百计的 MapReduce 程序,在 Google 的集群上,每天都有
1000 多个 MapReduce 程序在执行。
1、介绍
在过去的 5 年里,包括本文作者在内的 Google 的很多程序员,为了处理海量的原始数据,
已经实现了数以百计的、专用的计算方法。这些计算方法 用来处理大量的原始数据,比如
文档抓取(类似网络爬虫的程序)、Web 请求日志等等;也为了计算处理各种类型的衍生
数据,比如倒排索引、Web 文档的图 结构的各种表示形势、每台主机上网络爬虫抓取的页
面数量的汇总、每天被请求的最多的查询的集合等等。大多数这样的数据处理运算在概念
上很容易理解。然而由 于输入的数据量巨大,因此要想在可接受的时间内完成运算,只有
将这些计算分布在成百上千的主机上。如何处理并行计算、如何分发数据、如何处理错误
所有这 些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处
理。
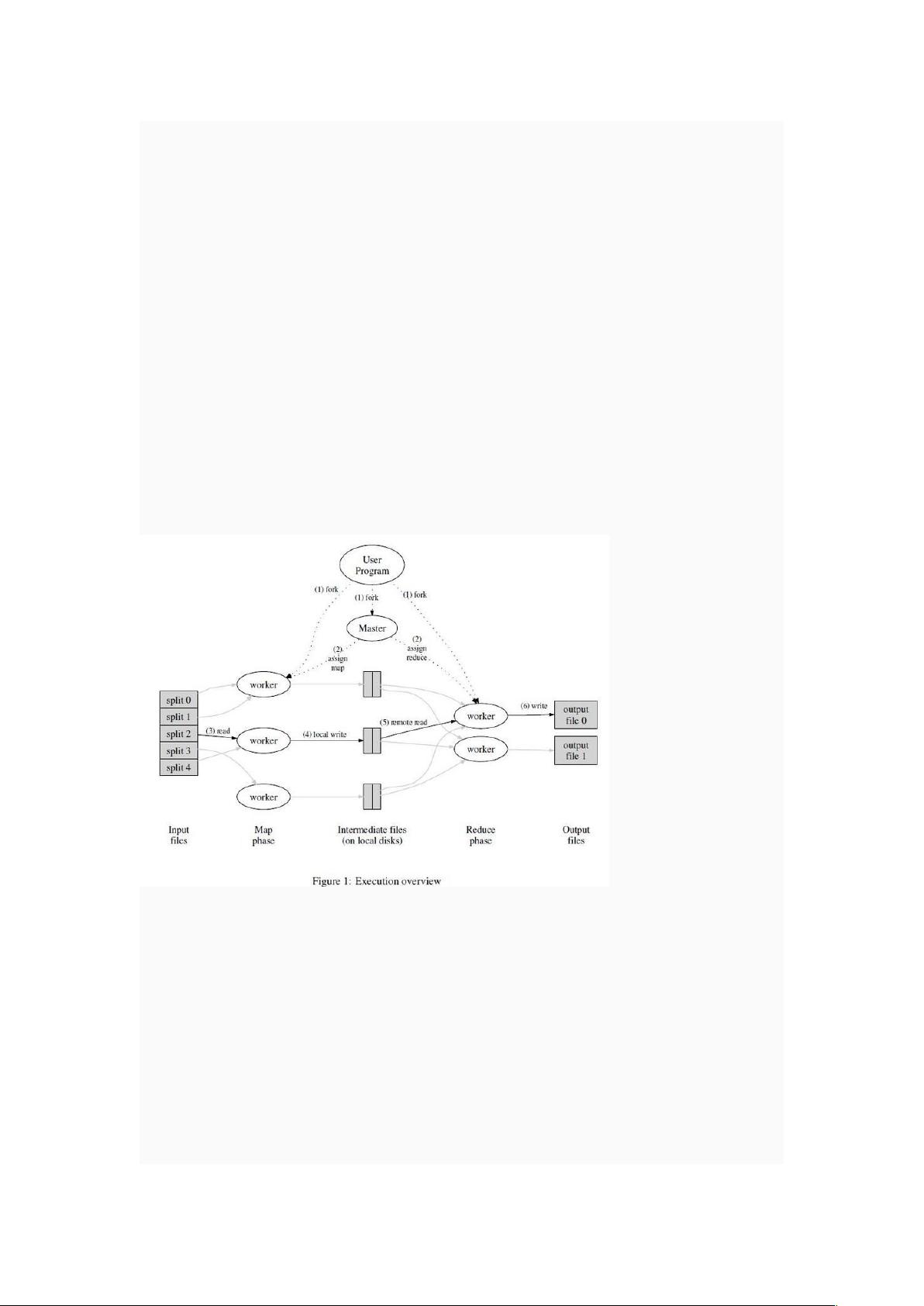
为了解决上述复杂的问题,我们设计一个新的抽象模型,使用这个抽象模型,我们只要表
述我们想要执行的简单运算即可,而不必关心并行计算、容错、 数据分布、负载均衡等复
杂的细节,这些问题都被封装在了一个库里面。设计这个抽象模型的灵感来自 Lisp 和许多
其他函数式语言的 Map 和 Reduce 的原 语。我们意识到我们大多数的运算都包含这样的操
作:在输入数据的“逻辑”记录上应用 Map 操作得出一个中间 key/value pair 集合,然后在
所有具有相同 key 值的 value 值上应用 Reduce 操作,从而达到合并中间的数据,得到一
个想要的结果的目的。使用 MapReduce 模型,再结合用户实现的 Map 和 Reduce 函数,
我们就可以非常容易的实现大规模并行化计算;通过 MapReduce 模型自带的“再 次执行”
(re-execution)功能,也提供了初级的容灾实现方案。


剩余19页未读,继续阅读
资源评论













