Java内存模型
需积分: 0 18 浏览量
2019-02-27
12:27:56
上传
评论
收藏 2.96MB PDF 举报


深入理解 Java 内存模型
juapk Android开发者社区【整理】
深入理解 Java 内存模型(一)——基础
并发编程模型的分类
在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体)。通信是
指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种:共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信。在消息传递的并发模
型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。
同步是指程序用于控制不同线程之间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个
方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java 的并发采用的是共享内存模型,Java 线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的 Java
程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
Java 内存模型的抽象
在 java 中,所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”这个术语代指实例域,静态
域和数组元素)。局部变量(Local variables),方法定义参数(java 语言规范称之为 formal method parameters)和异常处理器参数
(exception handler parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
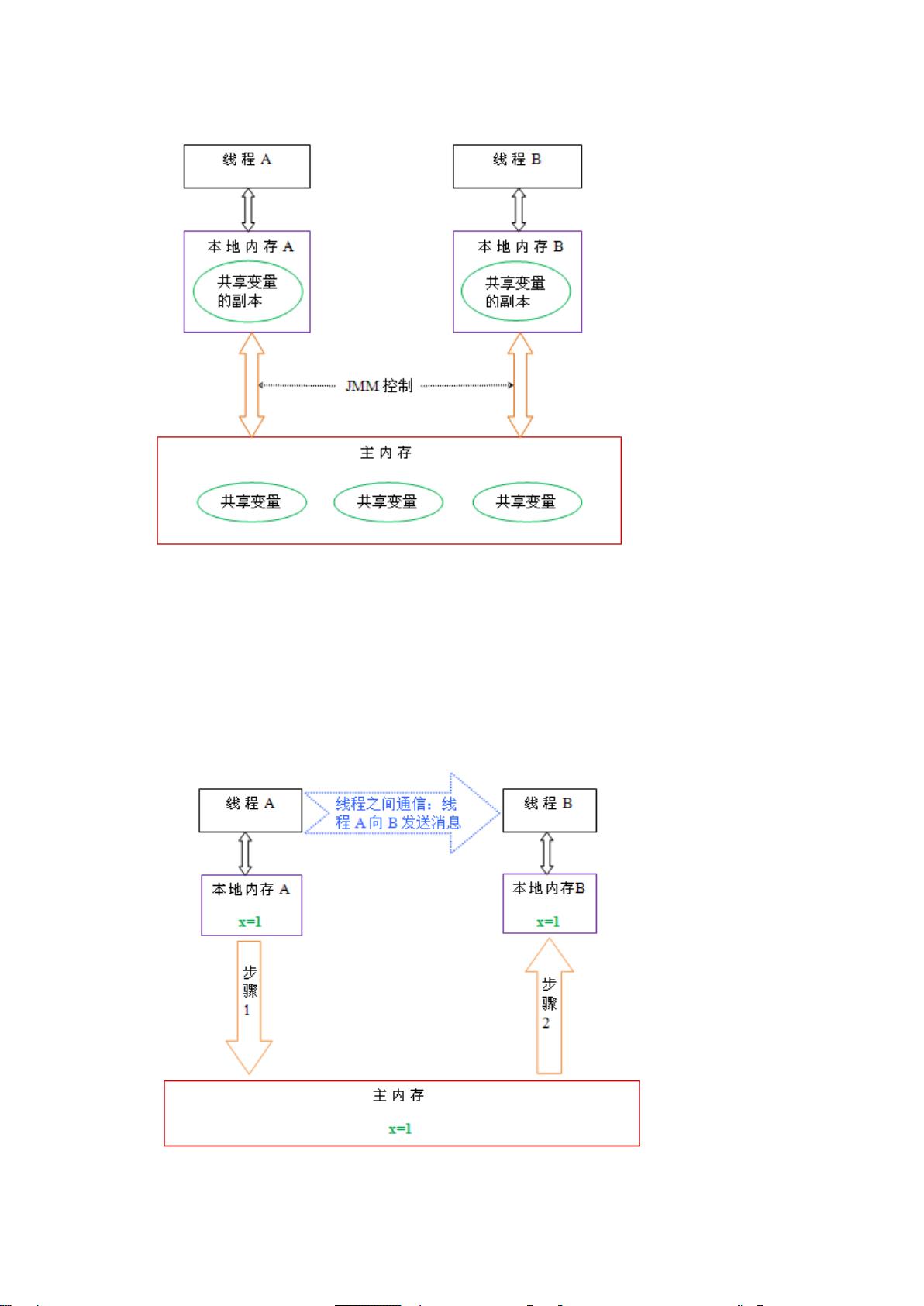
Java 线程之间的通信由 Java 内存模型(本文简称为 JMM)控制,JMM 决定一个线程对共享变量的写入何时对另一个线程可见。从抽象
的角度来看,JMM 定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私
有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是 JMM 的一个抽象概念,并不真实存在。
它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java 内存模型的抽象示意图如下:
这句话的理解很重要:
JMM将操作系统内存抽象
为单个线程独有的本地
内存和多个线程共享的
主存:
1. 主存:所有线程共
享,可以理解成物理内
存;
2. 本地内存:线程独
有、CPU不共享,代表着
cpu缓存、寄存器等
操作系统内存模型,顶
层是CPU,其抽象模型的
结构如下:
CPU(顶层)
--------
寄存器
高速缓存
(JMM中对应线程本地内
存,线程独有、CPU独
有,即多核CPU中,各个
CPU都有,但是不共享)
--------
内存
磁盘读写缓存
(JMM中对应着主存,多
个线程共享)
--------
硬盘
外部存储
栈帧的概念
JMM:描绘了共享变量在物理内存中存
取的抽象过程,他规定了对一个共享变
量的操作结果何时对其他线程可见
JMM屏蔽了底层平台的差异,对程序猿
提供了一个所有平台表现一致的内存模
型
1. java并发模型是基于内存共享的;
2. JMM抽象于现实的系统模型,这种抽
象的好处是可以最大程度的享受系统平
台的各种性能优化;
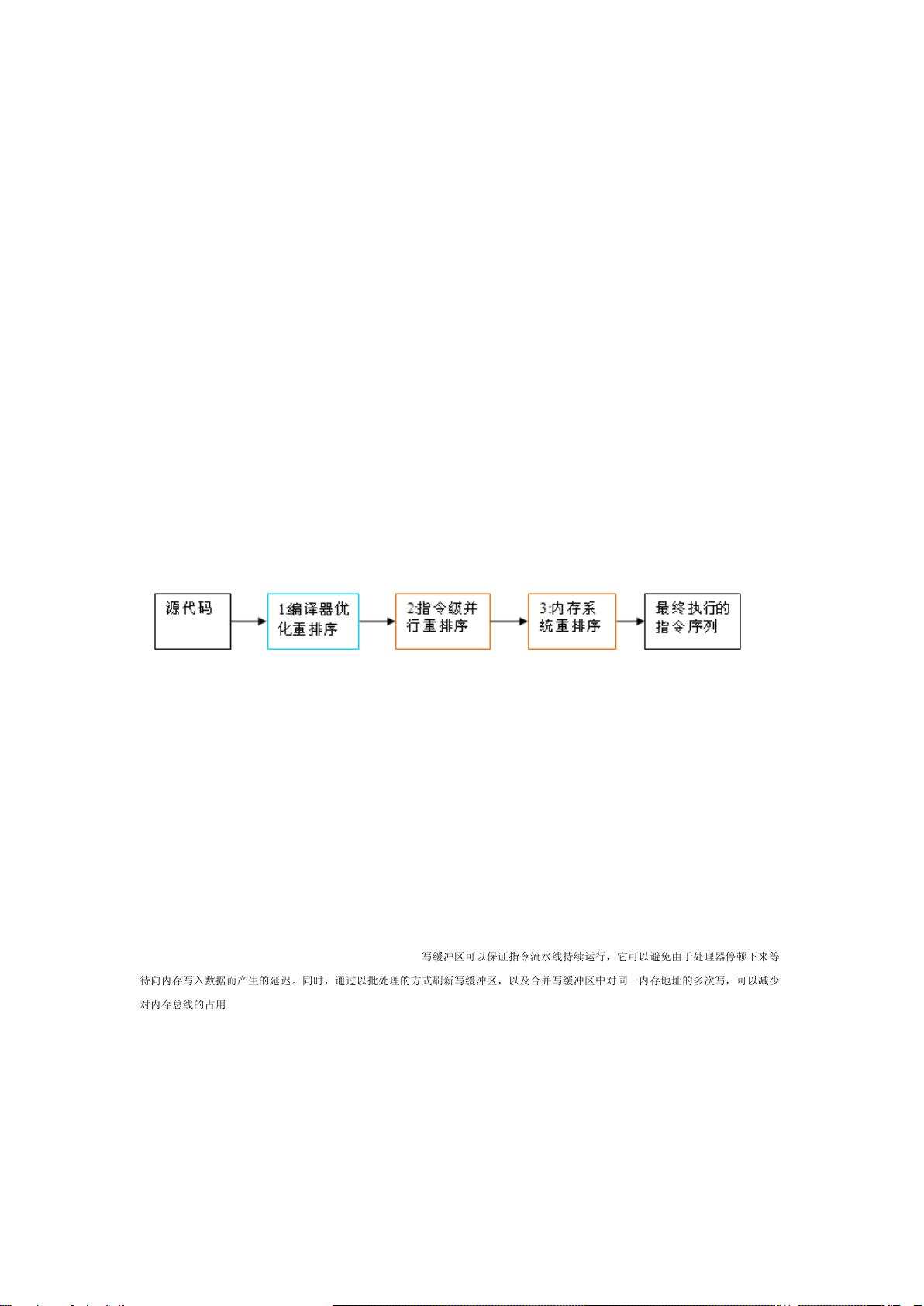
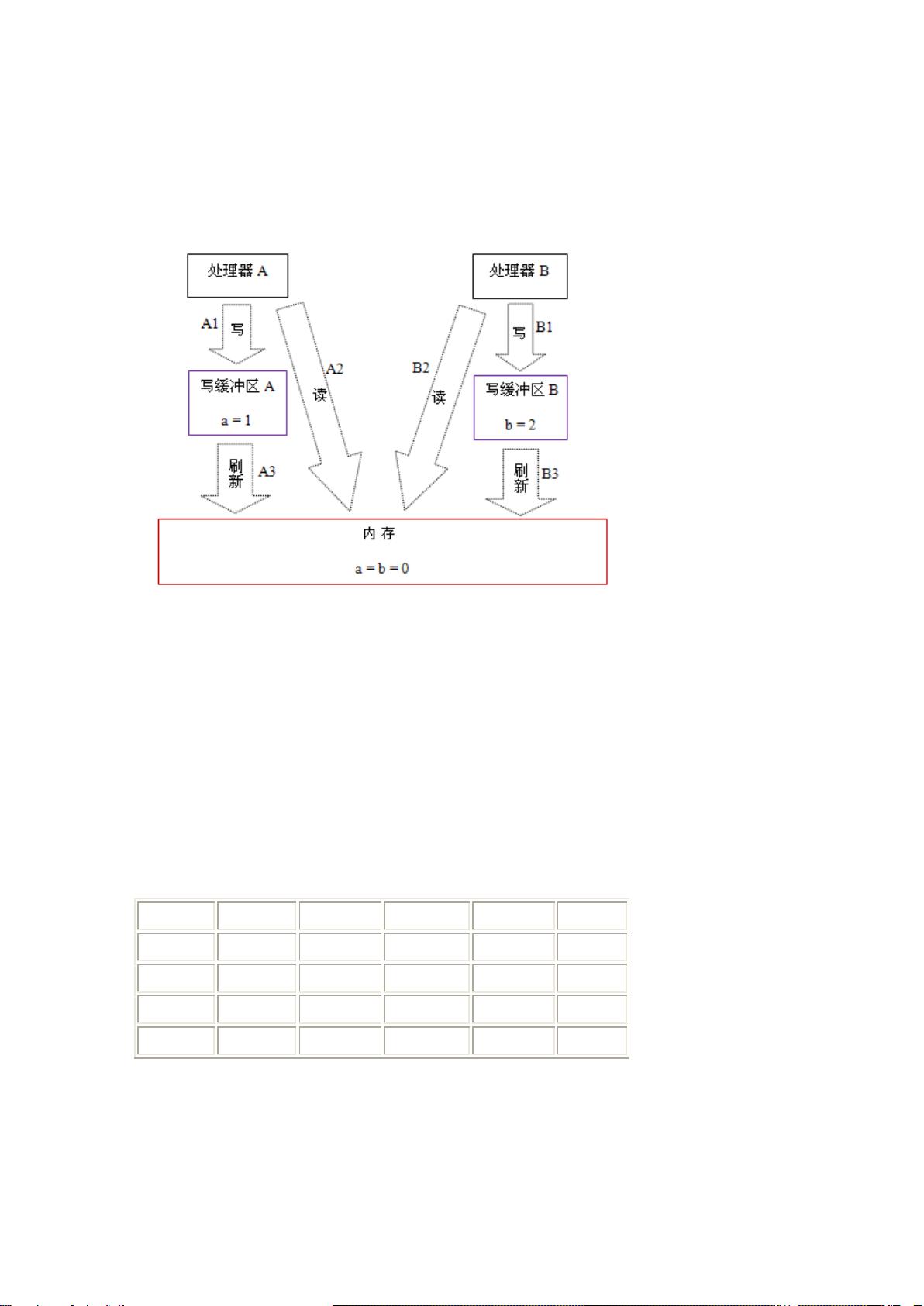
3. 在系统提供的性能优化中包含了重
排序,但是重排序会导致并发编程中的
一些问题,譬如顺序性和内存可见性;
4. 因此解决的方法是在适当的地方插
入内存屏障,抑制重排序;
1. java的并发编程模型是基于内存共
享的;
2. 操作系统的存储模型;
3. JMM的抽象模型基于现实中操作系统
的存储模型;

剩余52页未读,继续阅读






评论0
最新资源