





海洋生物识别
选题背景意义
近几十年来,海洋生物多样性的成像技术飞速发展并逐渐成熟。随着海洋生态的特殊性
及复杂性的日益增进,大量的图像或视频无法全部由人工处理,迫切需要识别相关内容、
分类和标记的自主流程。所以,建立健全完善、分布广泛的监测网络是长久以来研究者们
关注的问题。这种网络可以提供充足的有效信息与变量,并且能准确描述所观测物种的生
态动态。
项目方法和创新性
为了能够更为有效且精准的识别海洋生物所属类别,以用于在海底场景下对海洋生物
更好的监测效果,本文从三个方面实现海洋生物识别,并能够达到 的准确率,能够很
好的应用于真实海洋生物识别的场景。
本文为了提升模型的泛化能力,对原始数据进行随机化处理,使得模型能够应对非数
据集中的其他类型数据,达到更好的识别效果。
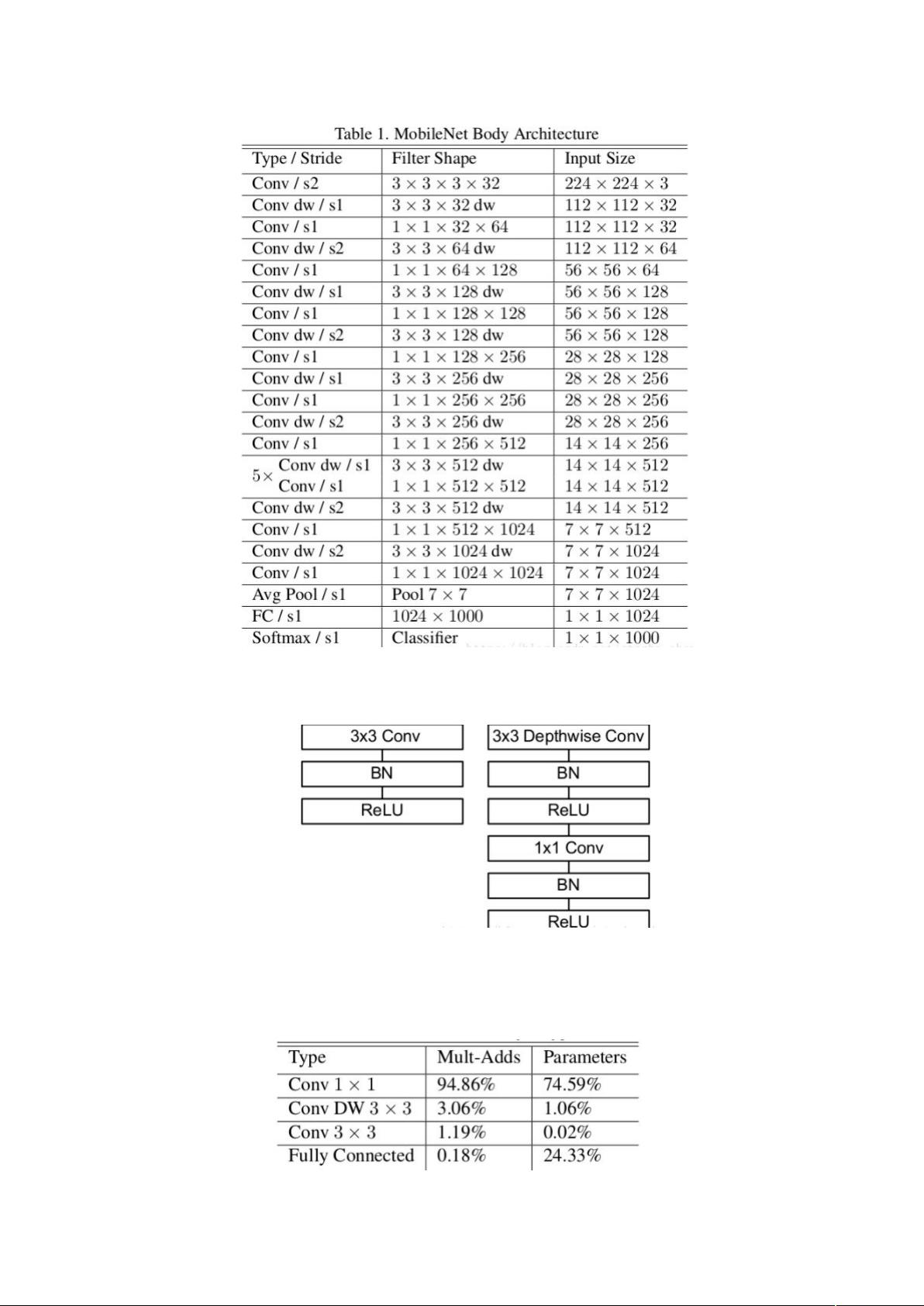
本文采用 深度级可分离卷积模型作为识别模型,该模型采用深度级可分离卷积
模式,大大减少了计算量和模型参数量。由于海洋生物识别通常需要集成在嵌入式环境下
对于模型的量级有着非常高的要求,因此 能够在海洋生物识别中取到很好地效
果是突破性的进展和创新。
本 文 在 深 度 学 习 模 型 的 基 础 上 加 入 了 迁 移 学 习 算 法 , 将 模 型 首 先 在
数据集上进行训练,然后将训练好的模型迁移到海洋生物识别场景下,大大减少
了训练所需时间,并提升了识别准确率。
遇到的困难和解决方案
在实验进行时,首先通过自己设计的模型结构实现海洋生物识别,模型结构包括 层
卷积层、 层池化层。通过模型卷积和下采样后,准确率仅能达到 左右,无法达到有
效的海洋生物监测目的。在这种情况下,我们采用 结合深度学习的方法,丰富
模型结构,提升最终的识别准确率,并达到了 的准确率效果。
实验设置、结果和分析
数据集介绍:
该鱼类数据是由台湾电力公司、台湾海洋研究所和垦丁国家公园在 年 月 日
至 年 月 日期间,在台湾南湾海峡、兰屿岛和胡比湖的水下观景台收集的鱼类图
像数据集,共生成了 个经过验证的鱼类图像。 整个数据集分为 个集群,每个集
群由一个代表性物种呈现,这是基于类群单系范围内的突触特征。 代表性图像表示下图中
显示的集群之间的区别,例如 有无成分(臀鳍、鼻、眶下)、具体数量( 条背鳍棘、
条背鳍棘刺)、特殊形状(第二条背鳍棘长)等。此图为代表 鱼种名称和检测数量。 数
据非常不平衡,最常见的物种比最少的物种多出大约 倍。















- 1
- 2
前往页