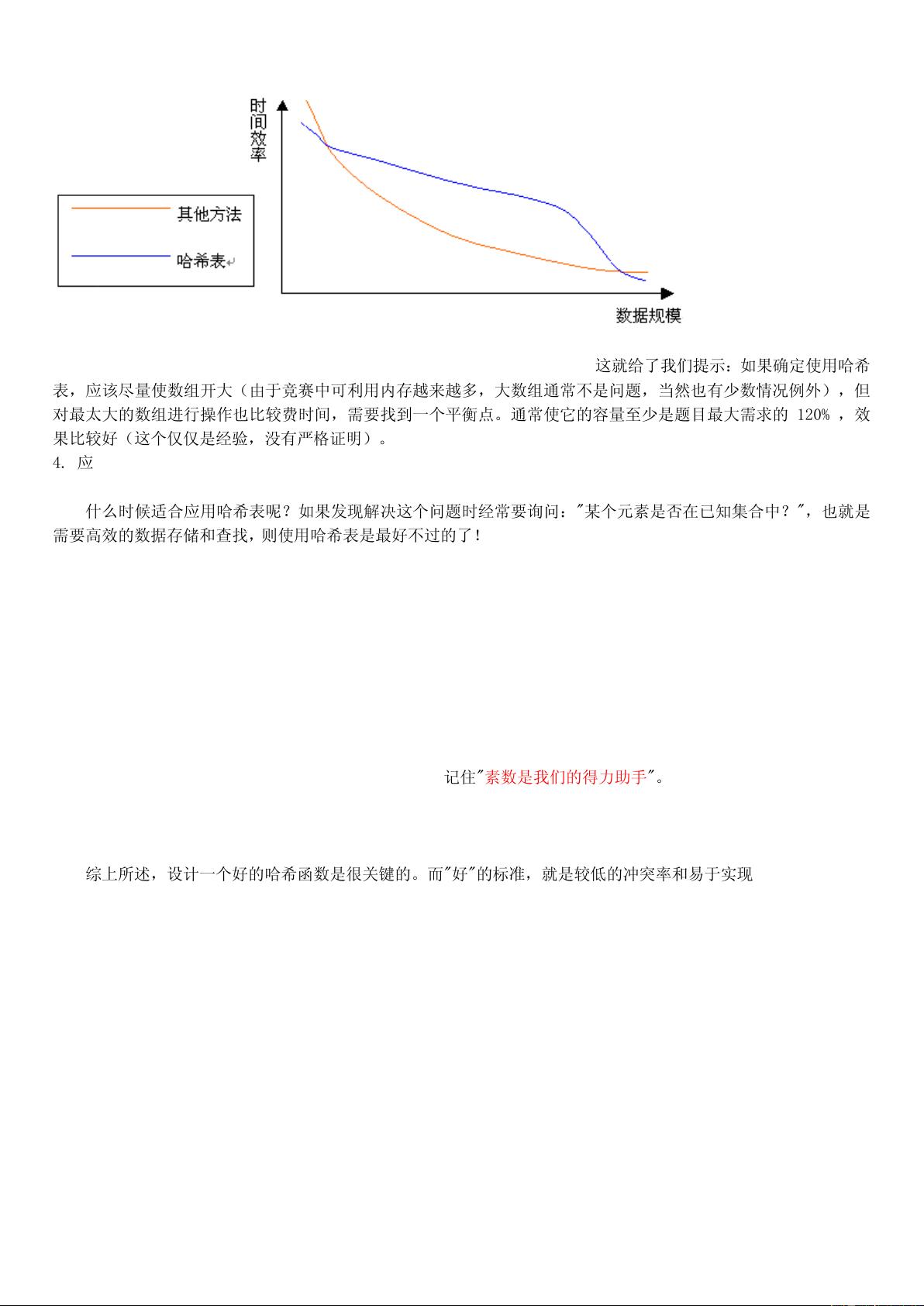
哈希表的应用,介绍了一些哈希表的用例


竞赛中哈希表的应用
简介:
哈希(Hash)表
前面讲的查找方法是基于比较的方法,查找效率依赖比较次数,其实理想的查找是希望不经比较,一次存取便
能得到所查记录。这样就必须在记录的存储位置和它的关键字之间建立一个确定的对应关系 f,查找 k 时,只要根据
这个对应关系 f 找到给定值 k 的像 f(k)。这种对应关系 f 叫哈希(hash)函数。按这种思想建立的表叫哈希表(也叫
散列表)。
哈希表存取方便但存储时容易冲突(collision):即不同的关键字可以对应同一哈希地址。如何确定哈希函数和
解决冲突是哈希表查找的关键。
1.哈希函数的构造方法
构造哈希函数的方法有很多,这里介绍几种常用的。
直接定址法:H(k)=k 或 H(k)=a*k+b(线形函数)
如:人口数字统计表
地址 1 2 3 ... 100
年龄 1 2 3 ... 100
人数 67 3533 244 ... 4
数字分析法:取关键字的若干数位组成哈希地址
如:关键字如下:若哈希表长为 100 则可取中间两位 10 进制数作为哈希地址。
81346532 81372242 81387422 81301367 81322817 81338967 81354157 81368537
平方取中法:关键字平方后取中间几位数组成哈希地址
折叠法:将关键数字分割成位数相同的几部分(最后一部分的位数可以不同)然后取几部分的叠加和(舍去进
位)作为哈希地址。
除留余数法:取关键字被某个不大于表长 m 的数 p 除后所得的余数为哈希地址。
H(k)=k mod p p<=m
随机数法:H(k)=rondom(k)。
2.处理冲突的方法
假设地址集为 0..n-1,由关键字得到的哈希地址为 j(0<=j<=n-1)的位置已存有记录,处理冲突就是为该关键字的记
录找到另一个"空"的哈希地址。在处理中可能得到一个地址序列 Hi i=1,2,...k 0<=Hi<=n-1),即在处理冲
突时若得到的另一个哈希地址 H1 仍发生冲突,再求下一地址 H2,若仍冲突,再求 H3...。怎样得到 Hi 呢?
开放定址法:Hi=(H(k)+di) mod m (H(k)为哈希函数;m 为哈希表长;di 为增量序列)
当 di=1,2,3,... m-1 时叫线性探测再散列。
当 di=1
2
,-1
2
,2
2
,-2
2
,3
2
,-3
2
,...,k
2
,-k
2
时叫二次探测再散列。
当 di=random(m)时叫伪随机探测序列。
例:长度为 11 的哈希表关键字分别为 17,60,29,哈希函数为 H(k)=k mod 11,第四个记录的关键字为 38,分
别按上述方法添入哈希表的地址为 8,4,3(随机数=9)。
再哈希法:Hi=RHi(key) i=1,2,...,k,其中 RHi 均为不同的哈希函数。
链地址法:这种方法很象基数排序,相同的地址的关键字值均链入对应的链表中。
建立公益区法:另设一个溢出表,不管得到的哈希地址如何,一旦发生冲突,都填入溢出表。
3.哈希表的查找
例:如下一组关键字按哈希函数 H(k)=k mod 13 和线性探测处理冲突所得的哈希表 a[0..15]:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
14
01
68
27
55
19
20
84
79
23
11
10
当给定值 k=84,则首先和 a[6]比,再依次和 a[7],a[8]比,结果 a[8]=84 查找成功。
当给定值 k=38,则首先和 a[12]比,再和 a[13]比,由于 a[13]没有,查找不成功,表中不存在关键字等于 38 的记录。


剩余21页未读,继续阅读
资源评论

 lcltmac2014-07-28很好的资源。
lcltmac2014-07-28很好的资源。












