基于Spring Cloud和ES事件流构建的商城微服务

A blog about open source software, graph databases, cloud native architectures, information
theory, artificial intelligence, and machine learning.
Kenny Bastani (http://www.kennybastani.com/)
Blog (http://www.kennybastani.com/) GitHub (http://www.github.com/kbastani)
Twitter (http://www.twitter.com/kennybastani)
LinkedIn (http://www.linkedin.com/in/kennybastani)
Event Sourcing in Microservices Using Spring Cloud and Reactor
Tuesday, April 19, 2016
When building applications in a microservice architecture, managing state becomes a
distributed systems problem. Instead of being able to manage state as transactions inside
the boundaries of a single monolithic application, a microservice must be able to manage
consistency using transactions that are distributed across a network of many different
applications and databases.
In this article we will explore the problems of data consistency and high availability in
microservices. We will start by taking a look at some of the important concepts and themes
behind handling data consistency in distributed systems.
Throughout this article we will use a reference application of an online store
(https://github.com/kbastani/spring-cloud-event-sourcing-example) that is built with
microservices using Spring Boot (http://projects.spring.io/spring-boot/) and Spring Cloud
(http://projects.spring.io/spring-cloud/). We’ll then look at how to use reactive streams
(http://www.reactive-streams.org/) with Project Reactor (https://projectreactor.io/) to
implement event sourcing in a microservice architecture. Finally, we’ll use Docker
(https://www.docker.com/) and Maven to build, run, and orchestrate the multi-container
reference application.
When building microservices, we are forced to start reasoning about state in an architecture
where data is eventually consistent. This is because each microservice exclusively exposes
resources from a database that it owns. Further, each of these databases would be
configured for high availability, with different consistency guarantees for each type of
database.
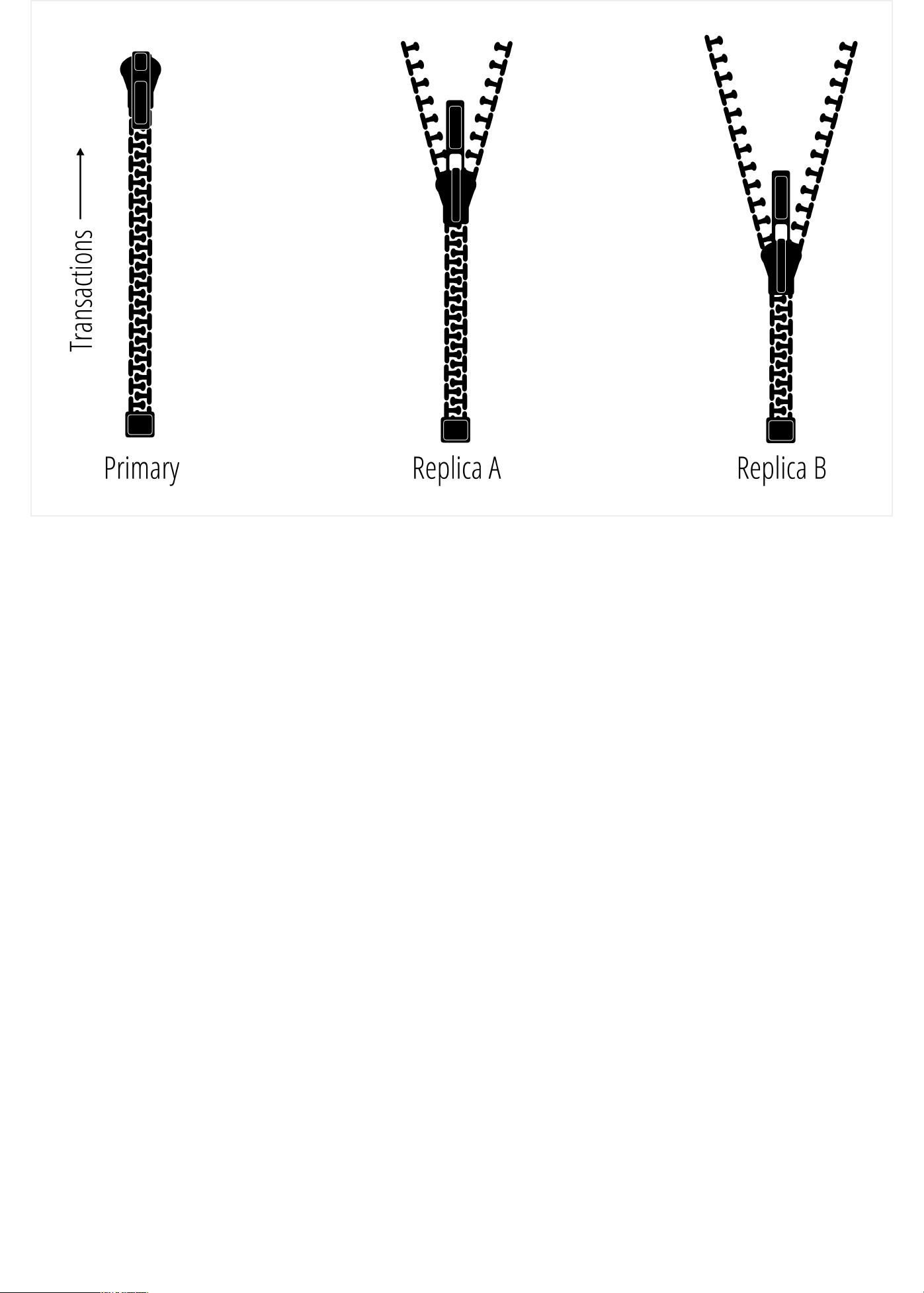
Eventual consistency (https://en.wikipedia.org/wiki/Eventual_consistency) is a model that is
used to describe some operations on data in a distributed system—where state is replicated
and stored across multiple nodes of a network. Typically, eventual consistency is talked
Eventual Consistency


剩余27页未读,继续阅读
资源评论

 DrLeesun2017-08-28太坑了,完全从外网弄回来的英文,还1个积分下载,外网的英文都看完了,下载下来费了我1个积分,不值,而且百度上还有翻译好的
DrLeesun2017-08-28太坑了,完全从外网弄回来的英文,还1个积分下载,外网的英文都看完了,下载下来费了我1个积分,不值,而且百度上还有翻译好的- 「已注销」2018-03-20没看懂。。。。












