百度-分布式应用解决方案——linkbase.docx

分布式应用解决方案——linkbase
一、分布式 linkbase 背景
1、背景介绍
网页链接库(简称 linkbase)是百度搜索引擎中重要的一部分,它存储的链接
数量、更新速度等直接影响到从整个互联网抓取网页的效率和质量,从而影响
搜索结果。
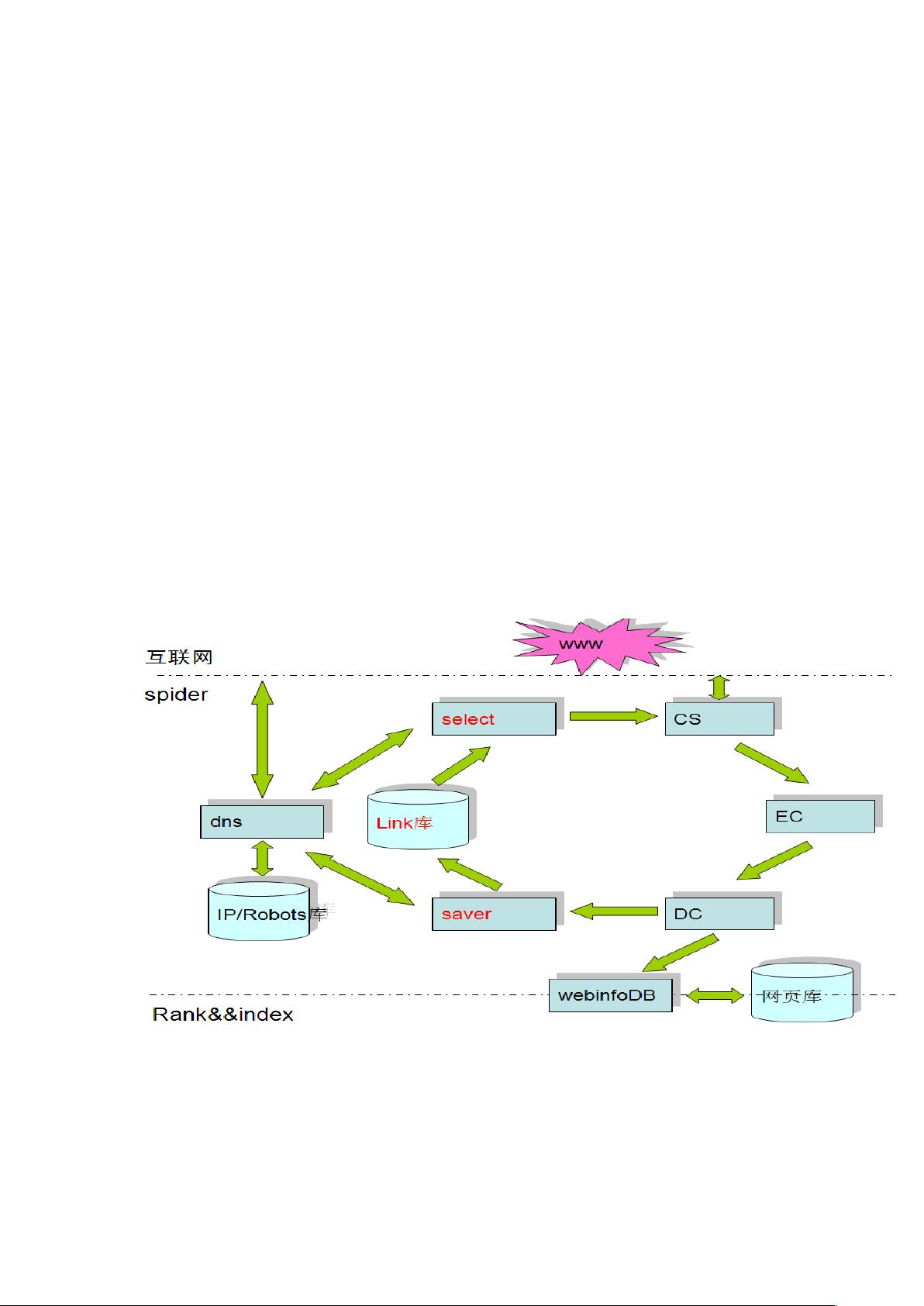
下面的示意图说明了 linkbase 在网页抓取和处理中的位置以及和其他模块、系
统的关系。
Link 库存储 spider 所需要的链接数据


剩余10页未读,继续阅读
资源评论

 woaiwerer2011-09-09写得不错,正好想去百度,希望面试的时候能加分,呵呵,多谢楼主分享!
woaiwerer2011-09-09写得不错,正好想去百度,希望面试的时候能加分,呵呵,多谢楼主分享!












