ARM NEON 使用手册


- 1 -
NEON support in the RealView compiler
William Munns
18 June 2007
Introduction
This paper provides a simple introduction to the NEON
TM
Vector-SIMD architecture. It
continues by looking at the compiler support for SIMD, both through automatic recognition
and through the use of intrinsic functions.
NEON is a hybrid 64/128 bit SIMD architecture extension to the ARM v7-A profile,
targeted at multimedia applications. Positioning NEON within the processor allows it to
share the CPU resources for integer operation, loop control, and caching, significantly
reducing the area and power cost compared with a CPU plus hardware accelerator
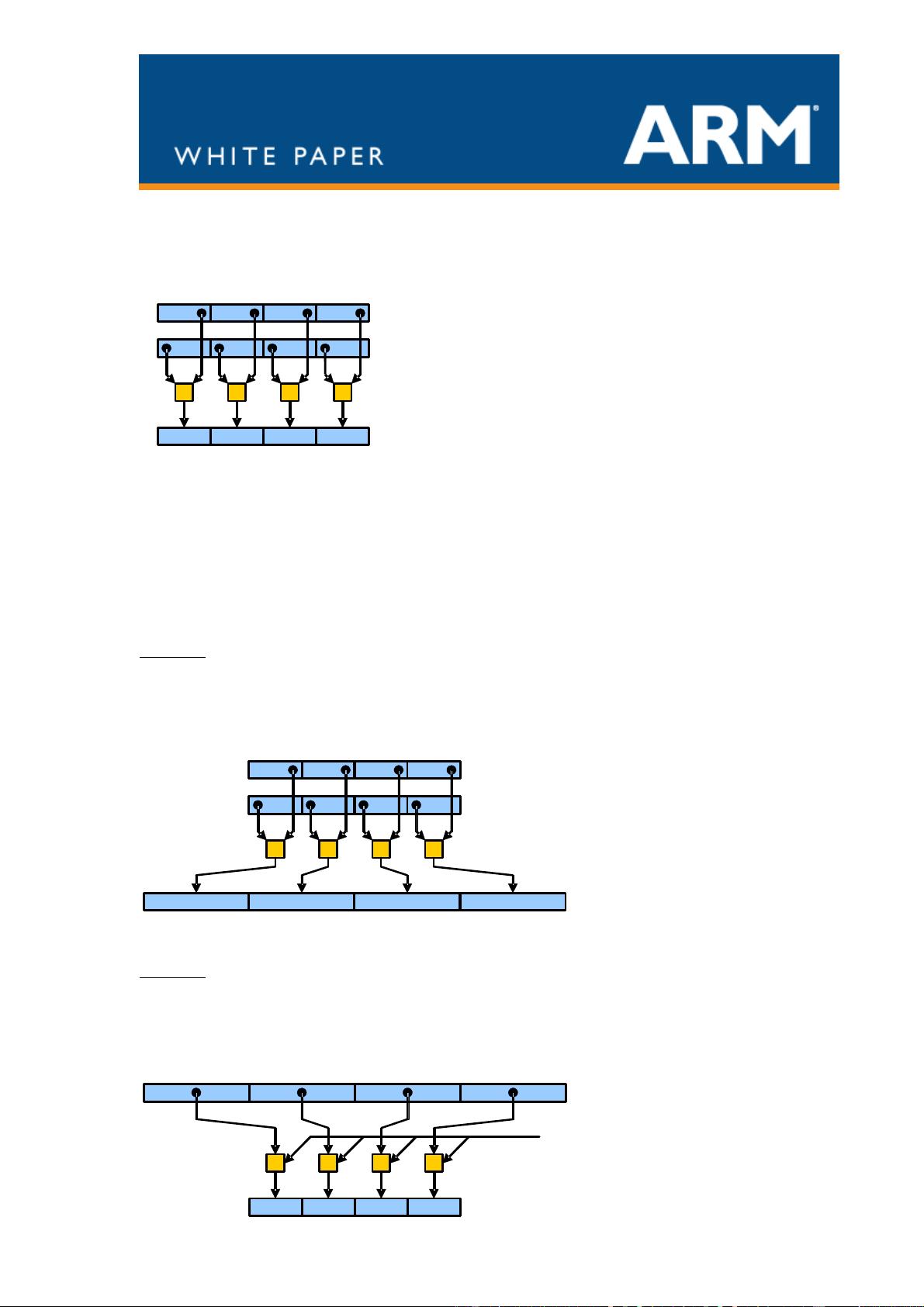
combination. SIMD (Single Instruction Multiple Data) is where one instruction acts on
multiple data items, usually carrying out the same operation for all data.
The use of NEON instead of a CPU plus hardware accelerator combination allows savings
to be made in software development time as it creates a much simpler programming model
without forcing the programmer to search for ad-hoc concurrency and scheduling points.
On the ARM Cortex™-A8 the NEON unit is positioned in the pipeline so that loads can
come directly from the L2 cache. This means that a much larger dataset can be held in the
cache than would be allowed when executing ARM or Thumb
®
-2 code.
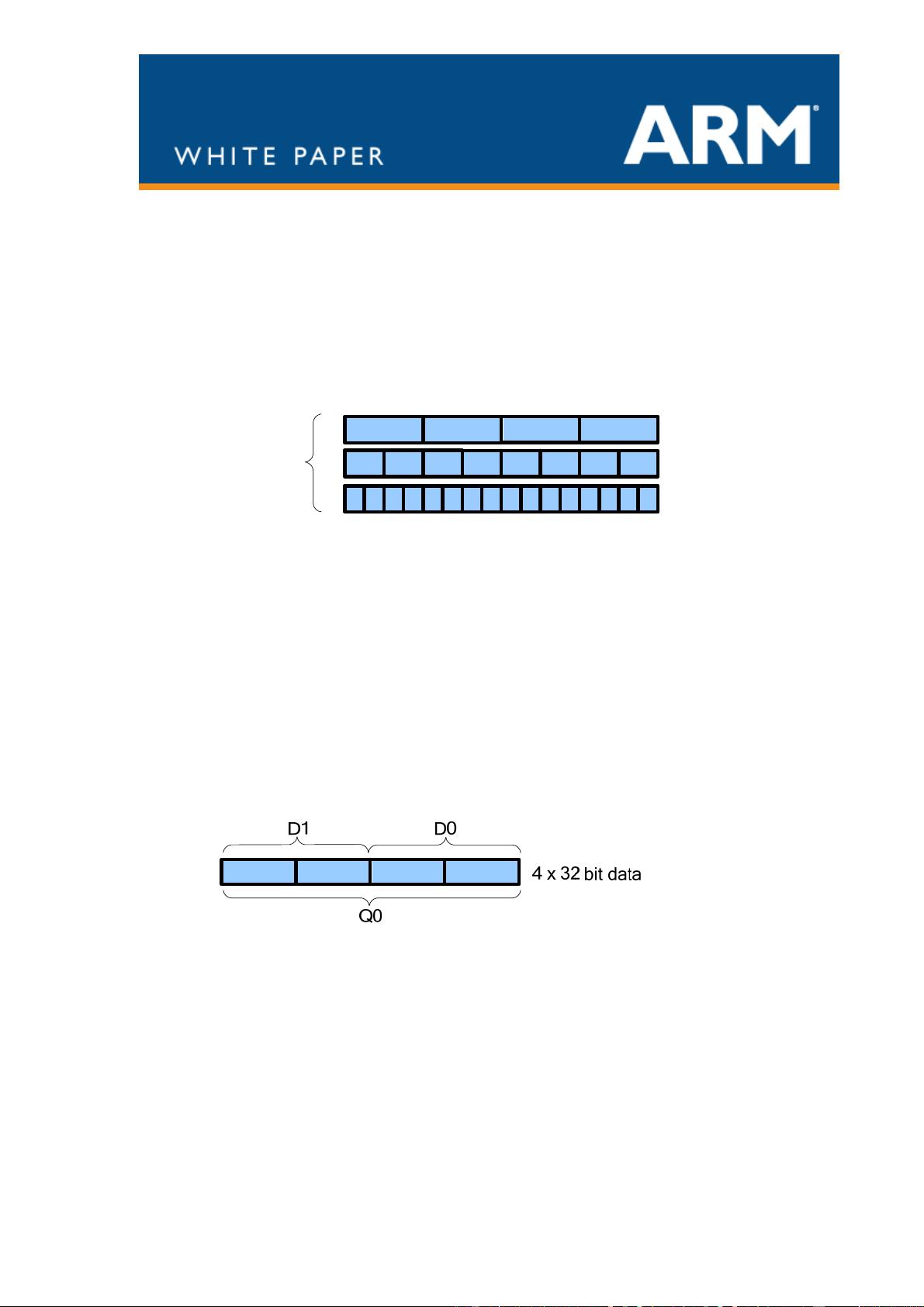
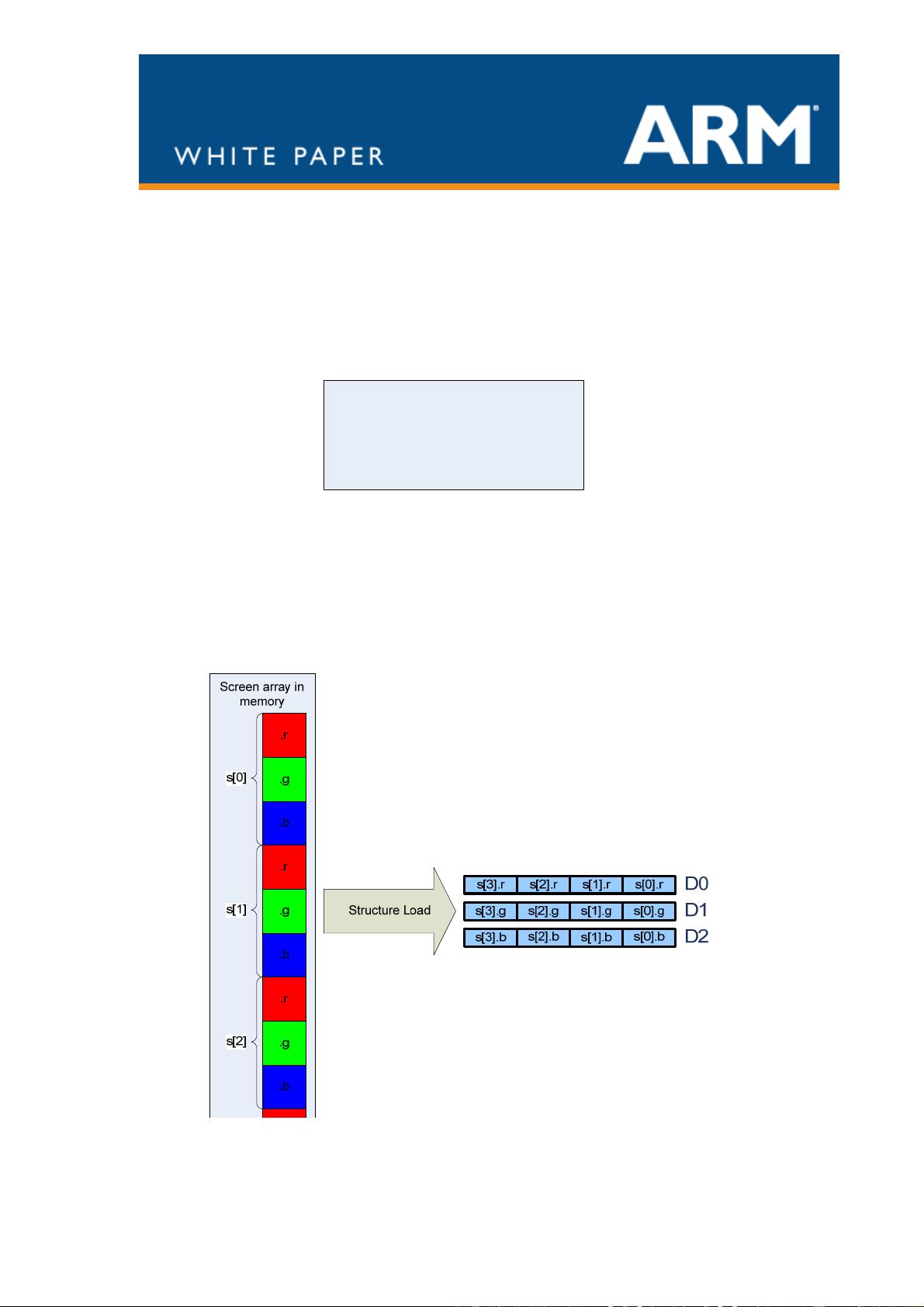
The NEON instruction set was designed to be an easy target for a compiler, including low
cost promotion/demotion and structure loads capable of accessing data from their natural
locations rather than forcing alignment to the vector size.
The RealView Development Tools
®
Suite version 3.1 supports NEON both in the standard
release using intrinsic functions and assembler, as well as through the vectorizing compiler
add-on which can recognise code sequences and automatically generate SIMD code. The
vectorizing compiler greatly reduces porting time, as well as reducing the requirement for
deep architectural knowledge.
© 2007 ARM Limited. All Rights Reserved.
ARM and RealView logo are registered
trademarks of ARM Ltd. All other trademarks
are the property of their respective owners and
are acknowledged

剩余20页未读,继续阅读
资源评论

 异次元空间19942018-02-04好用,我借助这个成功写了neon汇编优化画图
异次元空间19942018-02-04好用,我借助这个成功写了neon汇编优化画图












