目标跟踪中用到的各种深度学习方法的介绍
需积分: 48 54 浏览量
2018-09-19
21:28:52
上传
评论
收藏 1.04MB DOCX 举报


深度学习在目标跟踪中的应用
摘要: 人眼可以比较轻松的在一段时间内跟住某个特定目标。但是对机器而言,
这一任务并不简单,尤其是跟踪过程中会出现目标发生剧烈形变、被其他目标
遮挡或出现相似物体干扰等等各种复杂的情况。过去几十年以来,目标跟踪的
...
开始本文之前,我们首先看上方给出的 3 张图片,它们分别是同一个视频的第
1,40,80 帧。在第 1 帧给出一个跑步者的边框(bounding-box)之后,后续的第
40 帧,80 帧,bounding-box 依然准确圈出了同一个跑步者。以上展示的其实就
是目标跟踪(visual object tracking)的过程。目标跟踪(特指单目标跟踪)是指:给
出目标在跟踪视频第一帧中的初始状态(如位置,尺寸),自动估计目标物体
在后续帧中的状态。
人眼可以比较轻松的在一段时间内跟住某个特定目标。但是对机器而言,这一
任务并不简单,尤其是跟踪过程中会出现目标发生剧烈形变、被其他目标遮挡
或出现相似物体干扰等等各种复杂的情况。过去几十年以来,目标跟踪的研究
取得了长足的发展,尤其是各种机器学习算法被引入以来,目标跟踪算法呈现
百花齐放的态势。2013 年以来,深度学习方法开始在目标跟踪领域展露头脚,
并逐渐在性能上超越传统方法,取得巨大的突破。本文首先简要介绍主流的传
统目标跟踪方法,之后对基于深度学习的目标跟踪算法进行介绍,最后对深度
学习在目标跟踪领域的应用进行总结和展望。
经典目标跟踪方法
目 前 跟 踪 算 法可 以 被 分 为 产 生 式 (generative model) 和 判 别 式 (discriminative
model)两大类别。
产生式方法运用生成模型描述目标的表观特征,之后通过搜索候选目标来最小

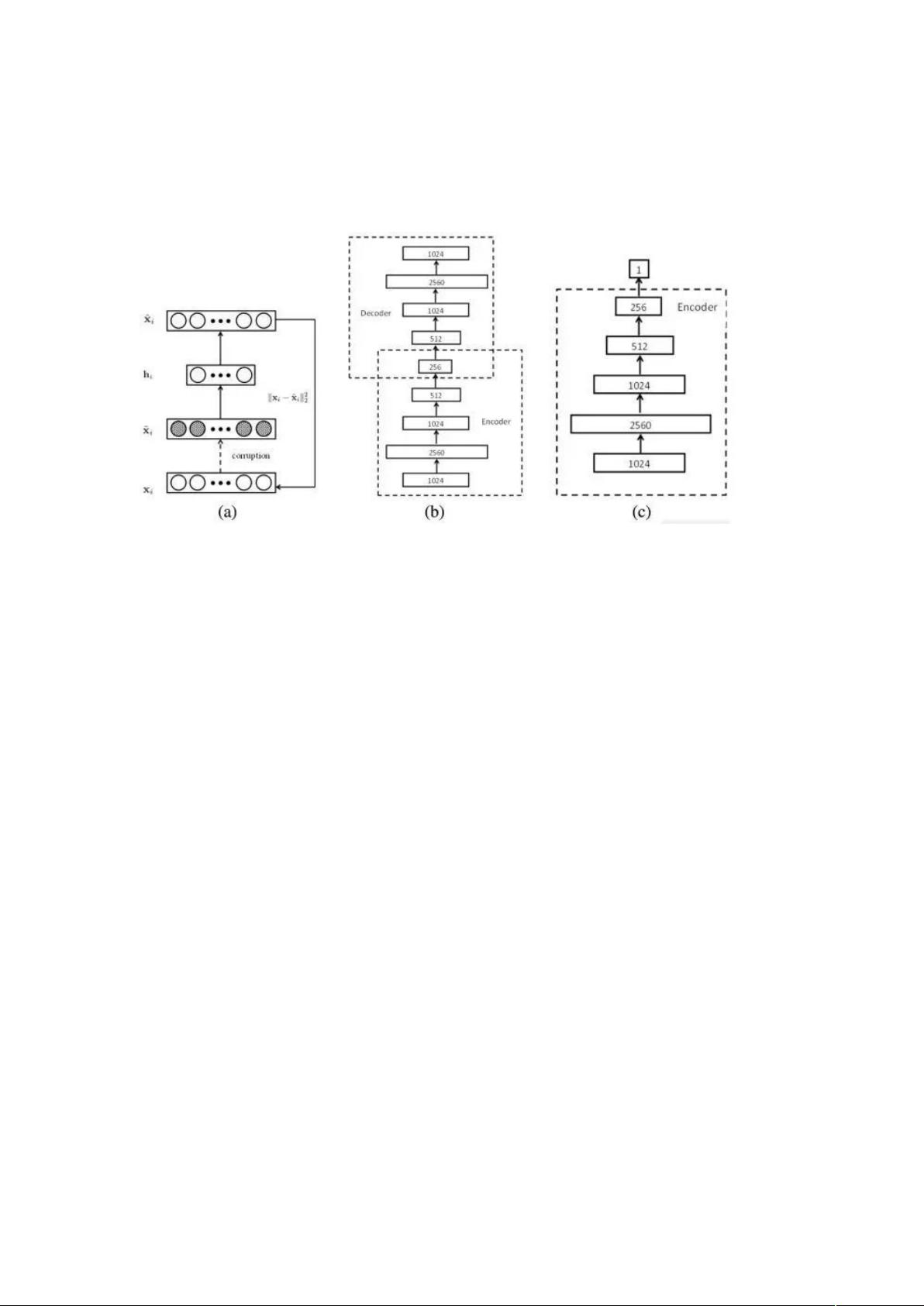


剩余22页未读,继续阅读
资源评论














