基于麦克风阵列声源定位系统的FPGA实现
159 浏览量
2020-10-22
15:08:51
上传
评论 8
收藏 194KB PDF 举报

基于麦克风阵列声源定位系统的基于麦克风阵列声源定位系统的FPGA实现实现
论述了基于麦克风阵列的声源定位技术的基本原理,给出了利用FPGA实现系统各模块的设计方法。重点介绍了
其原理和模块的电路实现,给出的基于FPGA设计实验结果表明,系统最大限度发挥了FPGA的优势、简化了系
统设计、缩短了设计周期、符合设计要求。
摘要:论述了基于
关键词:声源定位;时延估计;
声源定位,即确定一个或多个声源在空间中的位置,是一个有广泛应用背景的研究课题。基于麦克风阵列的声源定位技术
在视频会议、声音检测及语音增强等领域有重要的应用价值。
声源定位算法目前主要有3类:第一类算法是基于波束形成的方法。这种算法能够用于多个声源的定位,但是它存在着需要
声源和背景噪声先验知识以及对初始值比较敏感等缺点;第二类算法是基于高分辨率谱估计的方法。这种算法理论上能够对声
源方向进行有效估计,但是计算量较大,且不适于处理人声等宽带信号;第三类算法是基于到达时间差的方法。由于这种方法
原理简单,计算量较小,且易于实现,在声源定位系统中得到了广泛应用。根据以上介绍,本文决定选择第三类即基于到达时
间差的定位方法。
基于到达时间差声源定位算法包括2个步骤:
1)先进行时延估计,从中获得传声器阵列中相应阵元对之间的声音到达时延。常用的方法有最小均方自适应滤波法、互功率
谱相位法和广义互相关函数法。
2)利用时延估计进行方位估计,主要方法有角度距离定位法、球形插值法、线性插值法和目标函数空间搜索定位法。与其他
几种方法相比,基于广义互相关函数的方法计算量小、计算效率高。优点明显,故时延估计采用此方法。方位估计则采用精度
适中、易于实现的角度距离定位法。
FPGA具有高速处理能力,而且开发灵活,易于在线系统升级,能较大缩短系统的开发周期。为此,采用Ahera公司的
FPGA处理器件实现本系统。
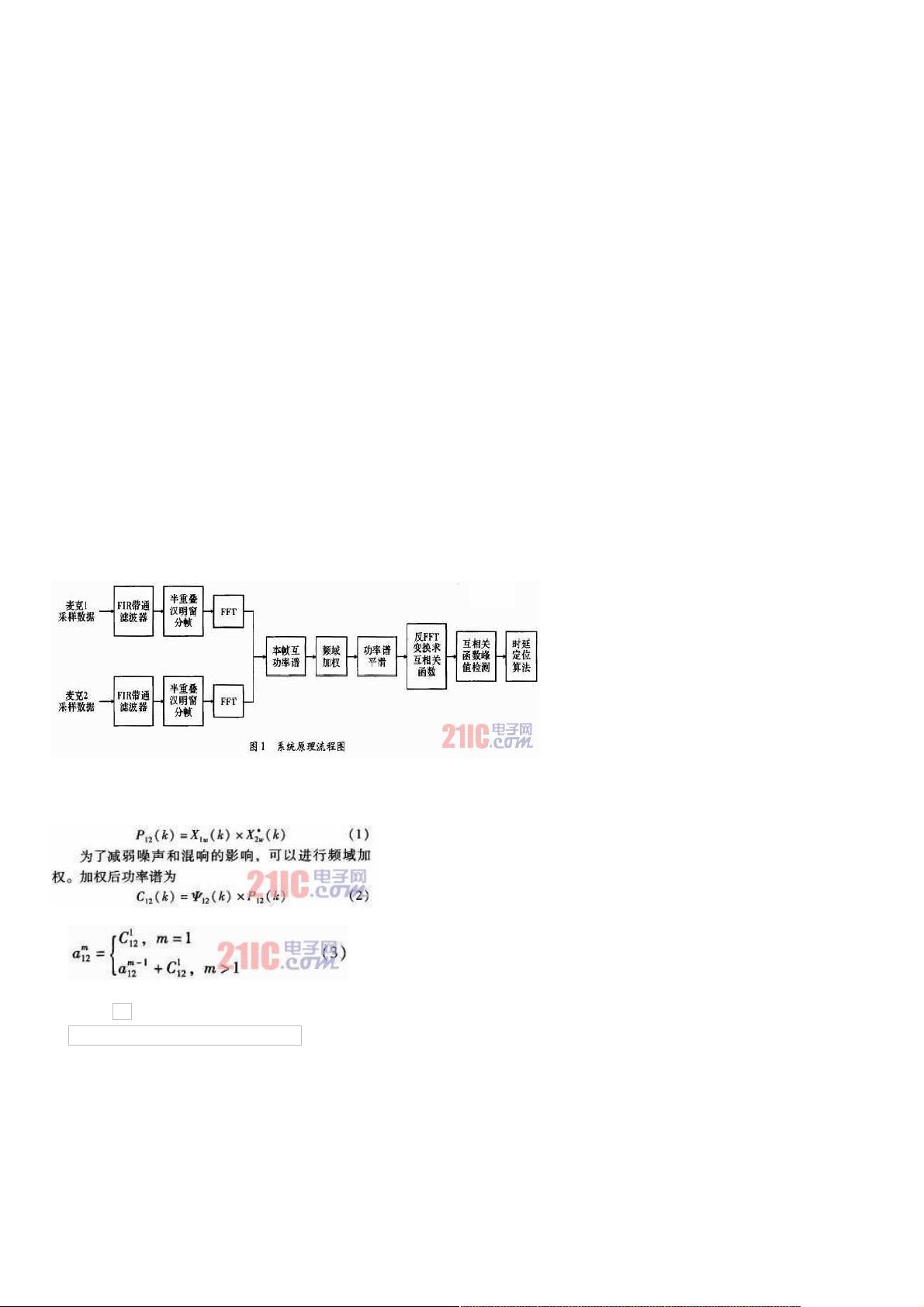
1 系统的基本原理及流程图
算法的结构流程如图1所示,首先由麦克1和2获得说话人的语音信号,再经过A/D采样和低通滤波器,最后得到待处理输
入语音信号,可以分别记为x1(n)和x2(n)。
经过FIR带通滤波器后,用半重叠汉明窗对x1(n)和x2(n)加窗可得X1w(n)和X2w(n),然后即可求得x1(n)和x2(n)的互功率谱
为
为进一步突出峰值,在频域加权后,可对麦克信号间的互功率谱平滑,得到
其中,m表示累加平滑的帧数。
接下来 对求傅里叶反变换,即可以得到麦克1和2间的广义互相关函数为
其峰值就是麦克1和2之间的时延。得到多对麦克间的时延后,由角度距离定位法,就可得到声源位置。
2 各模块设计实现
2.1 FIR带通滤波模块
为了消除噪声和回声干扰的影响,首先需要进行滤波。语音信号的带宽是0.3~3.4 kHz,因而需要设计一个带通滤波器
滤除语音信号带宽之外的噪声。为了使处理过的信号相位不发生变化即保持线性相位,需要采用FIR滤波器。
这里采用切比雪夫逼近法,由Matlab滤波器设计工具求得滤波器的各系数,乘以1024进行量化,转化为CSD编码以提高其
运行效率,最后由Verilog代码实现。
2.2 半重叠汉明窗模块
为了保证语音信号平稳性,一帧信号的时间窗长度选为10~30 ms。而采样器频率为10 kHz,为了便于FFT处理选择25.6
ms即帧长为256点。为了保证统计特征的连续性和得到更好的语音处理效果,各帧之间进行50%的重叠,即每次处理只更新
12.8 ms的数据。这样,一帧内的信号可以近似认为是平稳的。






评论0
最新资源