Mastering the Game of Go without Human Knowledge
David Silver*, Julian Schrittwieser*, Karen Simonyan*, Ioannis Antonoglou, Aja Huang, Arthur
Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy
Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, Demis Hassabis.
DeepMind, 5 New Street Square, London EC4A 3TW.
*These authors contributed equally to this work.
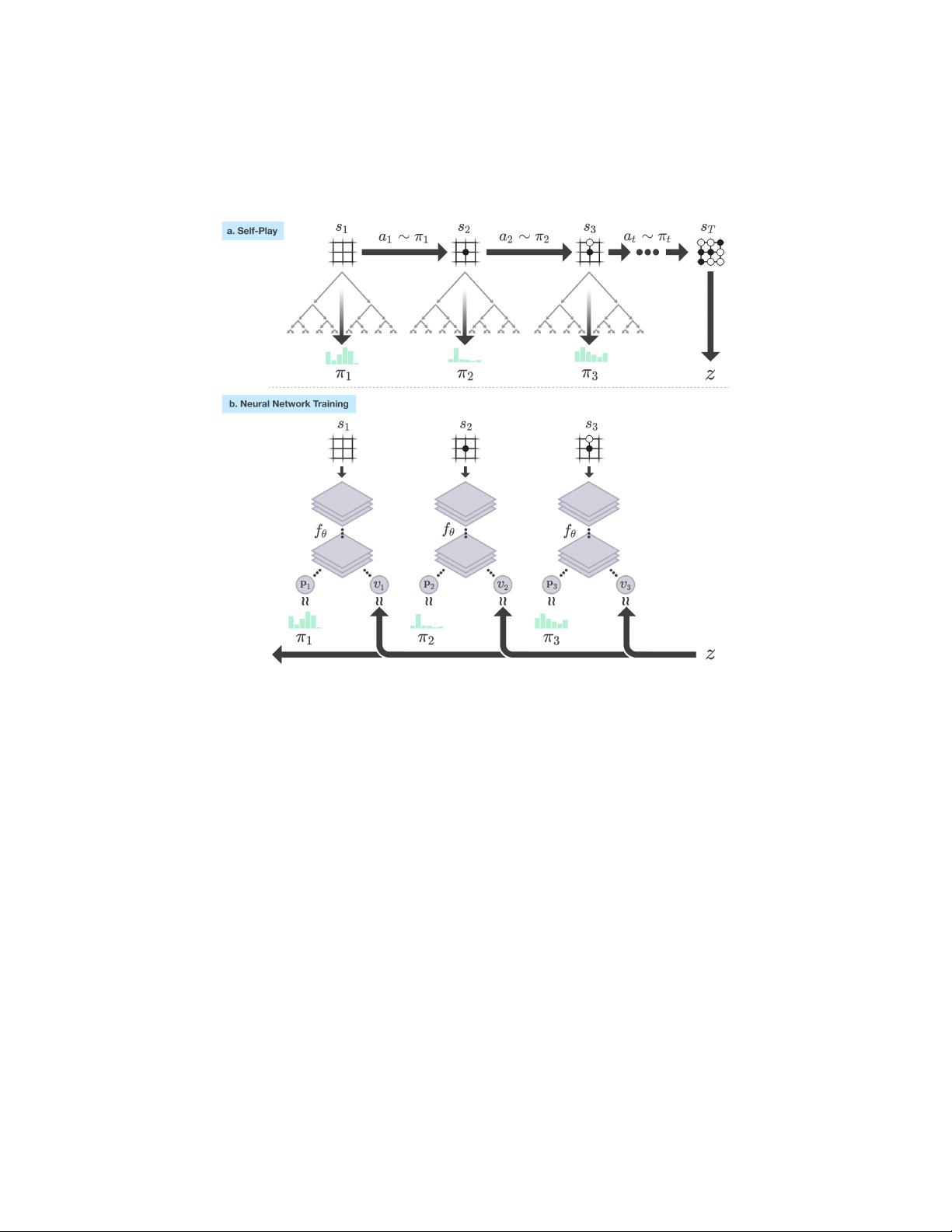
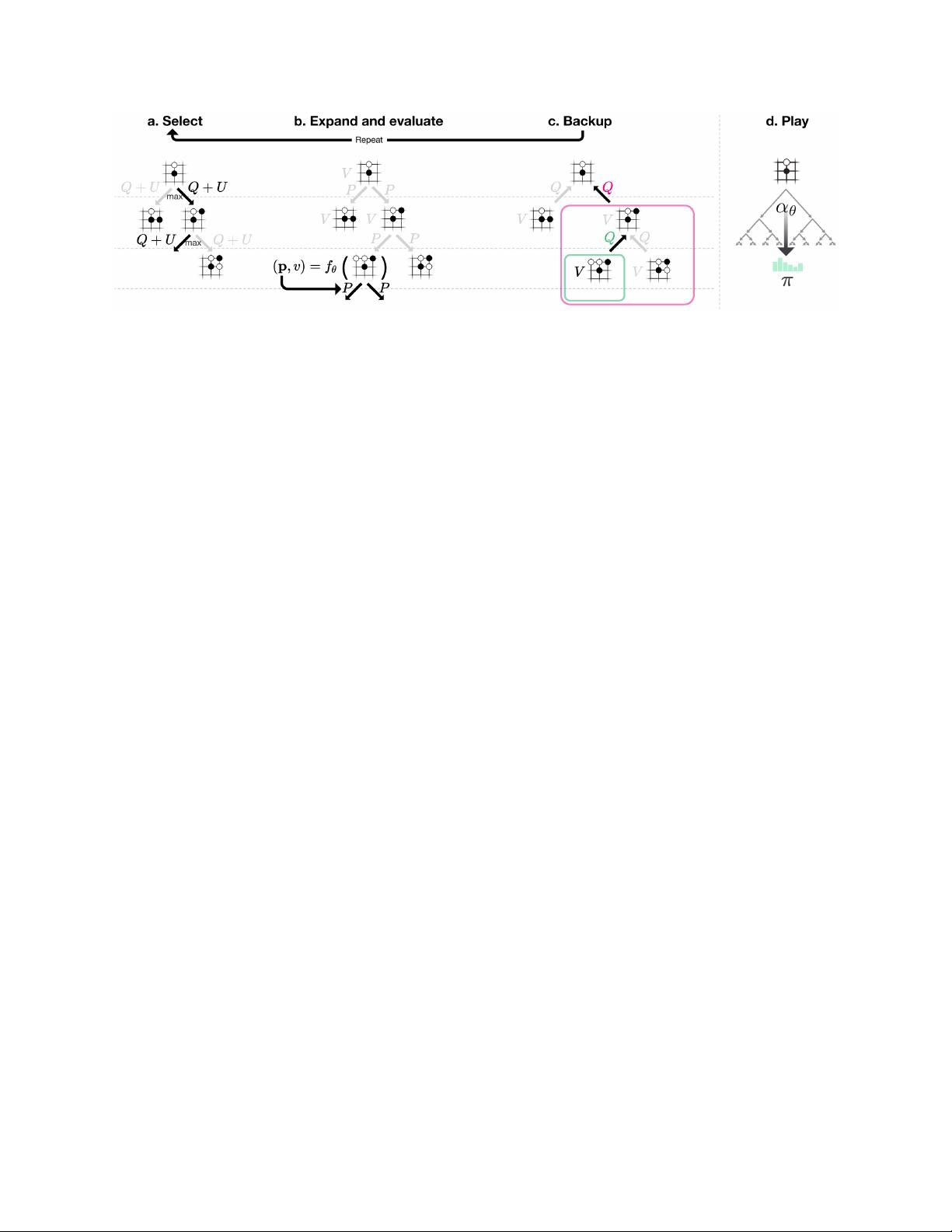
A long-standing goal of artificial intelligence is an algorithm that learns, tabula rasa, su-
perhuman proficiency in challenging domains. Recently, AlphaGo became the first program
to defeat a world champion in the game of Go. The tree search in AlphaGo evaluated posi-
tions and selected moves using deep neural networks. These neural networks were trained
by supervised learning from human expert moves, and by reinforcement learning from self-
play. Here, we introduce an algorithm based solely on reinforcement learning, without hu-
man data, guidance, or domain knowledge beyond game rules. AlphaGo becomes its own
teacher: a neural network is trained to predict AlphaGo’s own move selections and also the
winner of AlphaGo’s games. This neural network improves the strength of tree search, re-
sulting in higher quality move selection and stronger self-play in the next iteration. Starting
tabula rasa, our new program AlphaGo Zero achieved superhuman performance, winning
100-0 against the previously published, champion-defeating AlphaGo.
Much progress towards artificial intelligence has been made using supervised learning sys-
tems that are trained to replicate the decisions of human experts
1–4
. However, expert data is often
expensive, unreliable, or simply unavailable. Even when reliable data is available it may impose a
ceiling on the performance of systems trained in this manner
5
. In contrast, reinforcement learn-
ing systems are trained from their own experience, in principle allowing them to exceed human
capabilities, and to operate in domains where human expertise is lacking. Recently, there has been
rapid progress towards this goal, using deep neural networks trained by reinforcement learning.
These systems have outperformed humans in computer games such as Atari
6, 7
and 3D virtual en-
vironments
8–10
. However, the most challenging domains in terms of human intellect – such as the
1