raft算法,英文原版论文
需积分: 0 194 浏览量
2020-03-24
15:00:38
上传
评论
收藏 542KB PDF 举报


In Search of an Understandable Consensus Algorithm
(Extended Version)
Diego Ongaro and John Oust erhou t
Stanford University
Abstract
Raft is a consen sus algorithm for managing a replicated
log. It produces a result equivalent to (multi-)Paxos, and
it is as efficient as Paxos, but its structur e is different
from Paxos; this makes Raft more understandab le than
Paxos and also provides a better foundation for build-
ing practical system s. In order to enhance understandabil-
ity, Raft separates the key elements of consensus, such as
leader election, log replication, and safety, and it enforce s
a stronger degree of coherency to reduce the number of
states that must be considered. Results from a user study
demonstra te that Raft is easier for students to learn than
Paxos. Raft also includes a new m e chanism for changing
the cluster membership, which uses overlapping majori-
ties to gua rantee safety.
1 Introduction
Consensus algorithm s allow a collection of machin es
to work as a coheren t group that ca n survive the fail-
ures o f some of its members. Because of this, they play a
key role in building reliable large-scale software systems.
Paxos [15, 16] has dominated the discussion of consen-
sus algorithms over the last decade: most implementations
of consensus are based on Paxos or influenced by it, and
Paxos has become the primary vehicle used to teach stu-
dents about c onsensus.
Unfortu nately, Paxos is quite difficult to understand, in
spite of numerous attempts to make it more approachable.
Furthermore, its architecture requires complex chan ges
to support practical systems. As a result, both system
builders and students struggle with Paxos.
After struggling with Paxos ourselves, we set out to
find a new consensus algorithm that could provide a bet-
ter foundatio n for system building and education. Our ap-
proach was unusua l in that our primary goal was under-
standability: could we define a consensus algorithm for
practical systems and describe it in a way that is signifi-
cantly easier to learn than Paxos? Furtherm ore, we wanted
the algorithm to facilitate the development of intuitions
that are essential for system builders. It was important not
just for the algorithm to work, but for it to be obvious why
it works.
The result of this work is a consensus algorithm called
Raft. In designing Raft we applied specific techniques to
improve understand ability, including de composition (Raft
separates leader election, log rep lica tion, and safety) and
This tech report is an extended version of [32]; additional material is
noted with a gray bar in the margin. Published May 20, 2014.
state space reduction (relative to Paxos, Raft reduces the
degree of nondeterminism and th e ways servers can be in-
consistent with each othe r). A user study with 43 students
at two universities shows that Raft is significan tly easier
to understan d than Paxos: after learning both algorithms,
33 of these students were able to answer questions about
Raft better than questions about Paxos.
Raft is similar in m any ways to existing consensus al-
gorithms (most notably, Oki and Liskov’s Viewstamped
Replication [29, 22]), but it has several novel fea tures:
• Strong leader: Raft u ses a stronger form of leader-
ship than other consensus algorithms. For example,
log entries only flow fr om the leader to other servers.
This simplifies the management of the replicated log
and makes Raft easier to understand.
• Leader election: Raft uses randomized timers to
elect leaders. This adds only a small amount of
mechanism to the heartbeats already required for any
consensus algorithm, while resolving conflicts sim-
ply and rapidly.
• Membership changes: Raft’s mechanism for
changin g the set of servers in the cluster uses a new
joint consensus approach where the majorities of
two different configurations overlap during transi-
tions. This allows the cluster to continue opera ting
normally du ring configuration changes.
We believe that Raft is superior to Paxos and othe r con-
sensus algorithms, both for educatio nal purposes and as a
foundation for implementation. It is simpler and more un-
derstandable than other algorithms; it is described com-
pletely enough to m eet the needs of a practical system;
it has several open-source implementations and is used
by several companies; its saf ety properties have bee n for-
mally specified and proven; and its efficiency is compara-
ble to other algorithms.
The remainder of the paper intr oduces the replicated
state machine p roblem (Section 2), discusses the strength s
and weaknesses of Paxos (Section 3), describes our gen-
eral approach to u nderstandability (Section 4), presents
the Raft co nsensus algorithm (Sections 5–8), evaluates
Raft (Section 9), and discusses related work (Section 10).
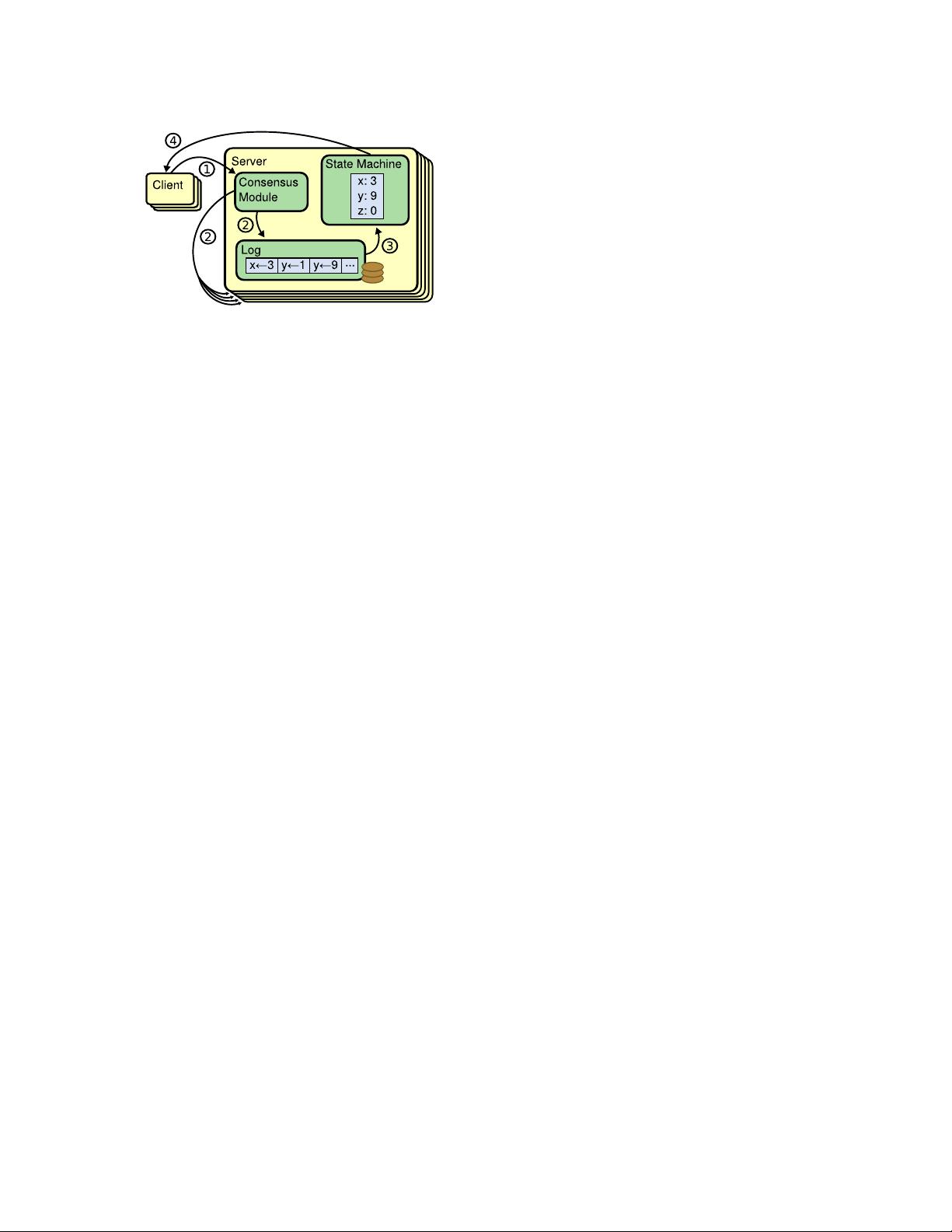
2 Replicated state machines
Consensus algorithms typically arise in the context of
replicated state machines [ 37]. In this approach, state m a-
chines on a collection of servers compute identical copies
of the same state an d can continue operating even if some
of the servers are down. Replicated state machines are
1

剩余17页未读,继续阅读
资源评论













