深度学习word2vec学习笔记.docx


深度学习 word2vec 笔记之基础篇
北流浪子
博客地址:
基础篇:
一.前言
伴随着深度学习的大红大紫,只要是在自己的成果里打上 字样,总会有
人去看。深度学习可以称为当今机器学习领域的当之无愧的巨星,也特别得到工业界的青
睐。
在各种大举深度学习大旗的公司中, 公司无疑是旗举得最高的,口号喊得最响
亮的那一个。 正好也是互联网界璀璨巨星,与深度学习的联姻,就像影视巨星刘德
华和林志玲的结合那么光彩夺目。
巨星联姻产生的成果自然是天生的宠儿。 年末, 发布的 !" 工具引
起了一帮人的热捧,互联网界大量 公司的粉丝们兴奋了,从而 公司的股票开
始大涨,如今直逼苹果公司。
在大量赞叹 !" 的微博或者短文中,几乎都认为它是深度学习在自然语言领域的
一项了不起的应用,各种欢呼“深度学习在自然语言领域开始发力了”。
互联网界很多公司也开始跟进,使用 !" 产出了不少成果。身为一个互联网民工,
有必要对这种炙手可热的技术进行一定程度的理解。
好在 !" 也算是比较简单的,只是一个简单三层神经网络。在浏览了多位大牛的
博客,随笔和笔记后,整理成自己的博文,或者说抄出来自己的博文。
二.背景知识
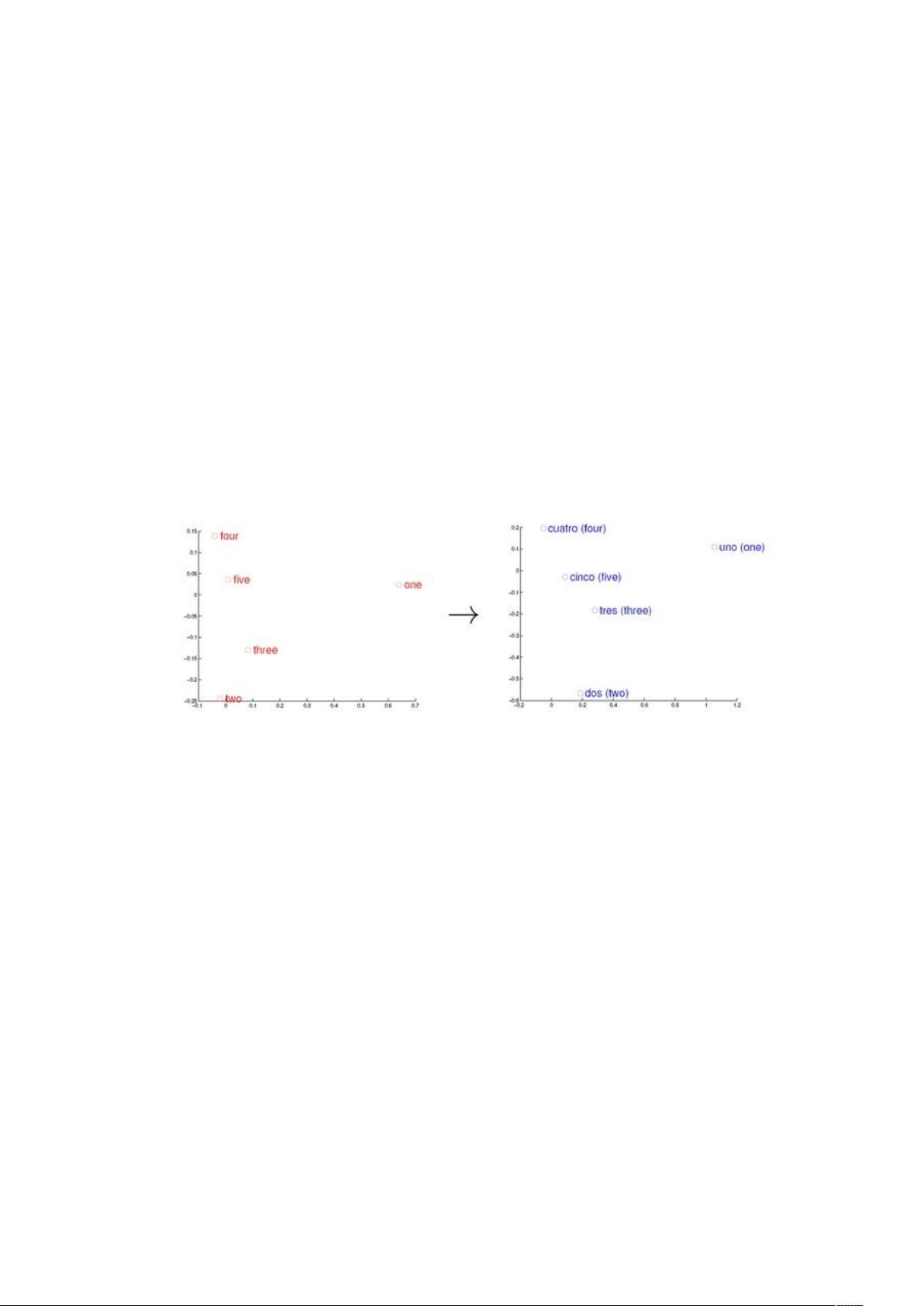
2.1 词向量
自然语言处理(#$%)相关任务中,要将自然语言交给机器学习中的算法来处理,通
常需要首先将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东
西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式了。



剩余33页未读,继续阅读






评论30
最新资源