基于关键词表达式模型的文本自动分类系
统的研究与实现
Research and Implementation of Text Categorization
System Based on Keyword Expressions
常毅() 张鑫( 谭建龙(Tan jianlong) 白硕(Bai shuo)
(中国科学院计算技术研究所 Institute of Computing Technology , CAS 100080)
E-mail: changyi@ncic.ac.cn
中图法分类号 TP391
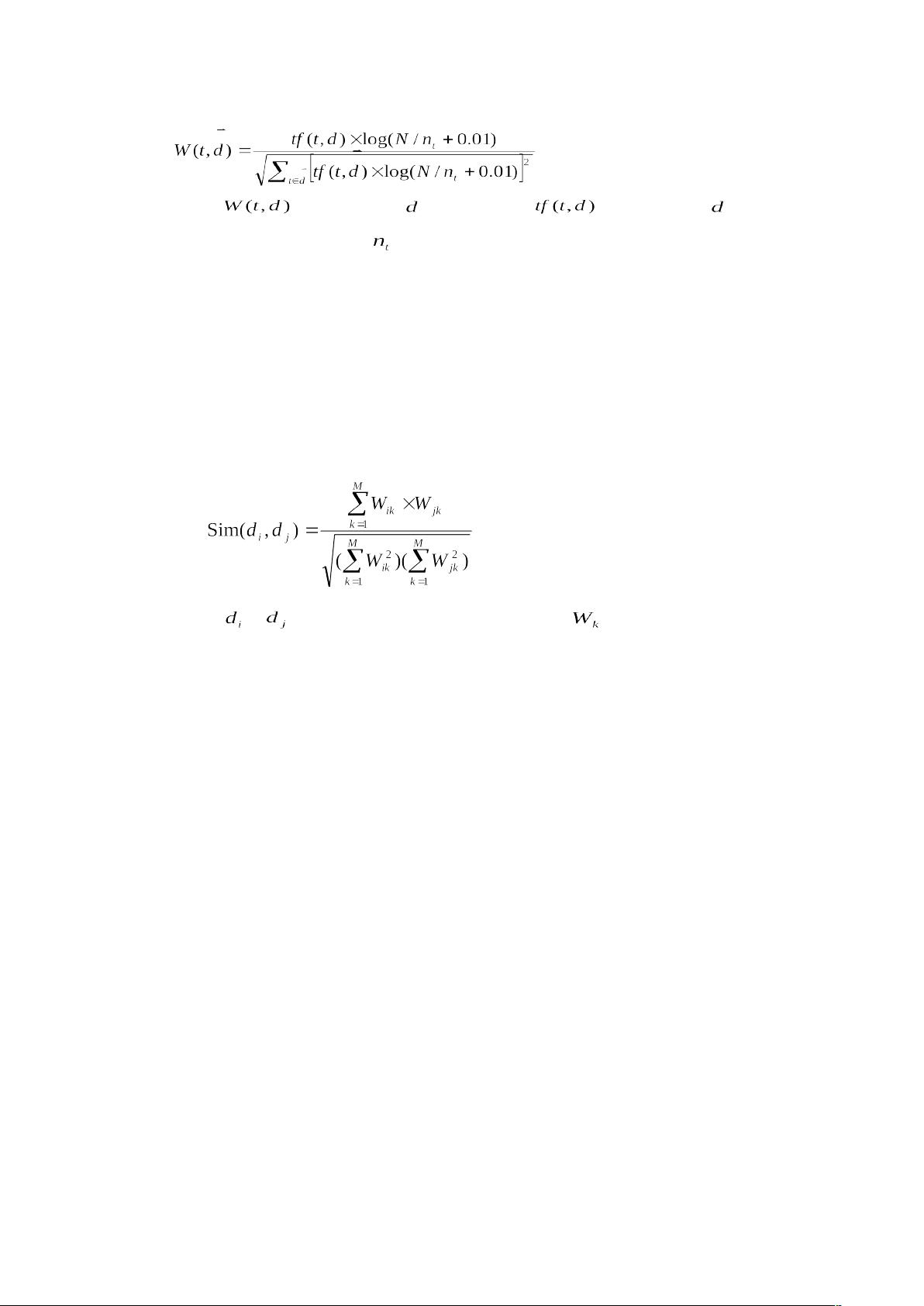
摘 要:文本提出了一种新的基于关键词表达式模式的文本向量空间表示模型,在这个表示
模型基础上实现了一个的自动分类系统。相对于只使用文本中词语的频率的文本向量空间
模型,这种新的模型在可以计算的前提下,使用了词语之间的相对位置信息,从而可以解
决部分词语向量空间模型表示的不足。本文描述了使用这种模型的自动文本分类系统。包
括分类系统的结构,特征提取,文本相似度计算公式,并给出了评估方法和实验结果。
关键词:文本分类 中文信息处理 向量空间模型,关键词表示式,关键词匹配
Abstract:In recent years , information processing turns more and more important for us to get
useful information . Text Categorization, the automated assigning of natural language texts to
predefined categories based on their contents, is a task of increasing importance. This paper gives
a research to several key techniques about Text Categorization , including Vector Space Model ,
Feature Extraction , Machine Learning . It also describes a text categorization model based on
VSM, and gives the evaluations and results .
Key words:Text Categorization Chinese Information Processing Vector Space Model
1 引言
基于统计技术的文本分类系统能依据文本的语义将大量的文本自动分门别类,从而更
好地帮助人们把握文本信息。近年来,文本分类技术已经逐渐与搜索引擎、信息推送、信
息过滤等信息处理技术相结合,有效地提高了信息服务的质量。
本文主要探讨了新的文本表示模型和这种模型下的一个分类系统的实现,第一部分为
引言,第二部分描述了文本分类解决的问题并对其性能评估方法进行了介绍,第三部分探
讨了基于关键词表达式的文本表示模型,第四部分给出了我们实现的的文本分类系统,第
五部分是该系统的实验结果和计算复杂度分析,第六部分总结和对将来工作的设想。