运动员的运动员的自动检测..论文
需积分: 0 120 浏览量
2012-02-28
16:53:25
上传
评论
收藏 1.18MB PDF 举报


IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 20, NO. 3, MARCH 2010 351
Automatic Detection and Analysis of Player Action
in Moving Background Sports Video Sequences
Haojie Li, Jinhui Tang, Member, IEEE, Si Wu, Yongdong Zhang, and Shouxun Lin, Member, IEEE
Abstract—This paper presents a system for automatically
detecting and analyzing complex player actions in moving back-
ground sports video sequences, aiming at action-based sports
videos indexing and providing kinematic measurements for coach
assistance and performance improvement. The system works
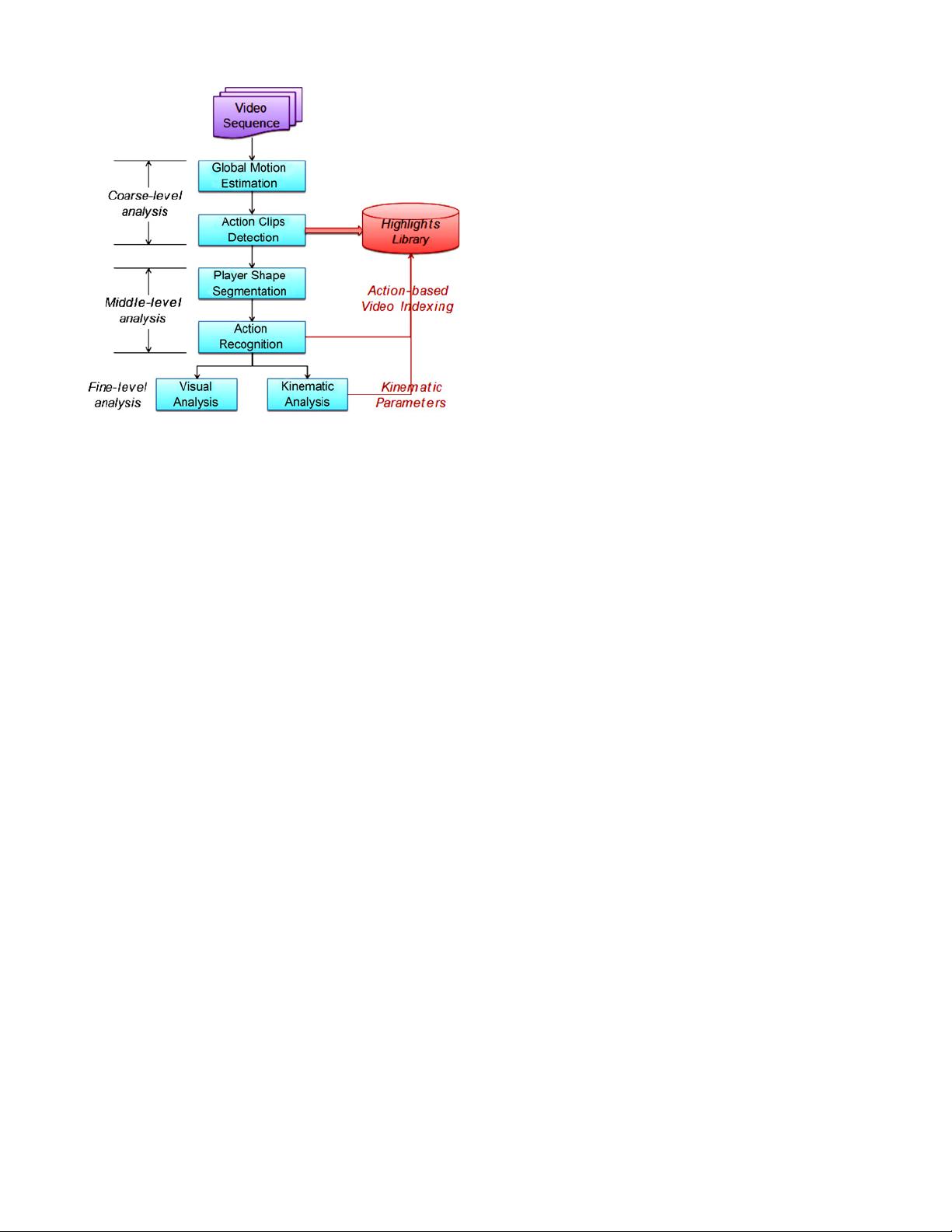
in a coarse-to-fine fashion. For an input video, in the coarse
granularity level, we automatically segment the highlights, that
is, the video clips containing the desired action as summaries
for general user viewing purposes; in the middle granularity
level, we recognize the action types to support action-based
video indexing and retrieval; and finally in the fine granularity
level, the critical kinematic parameters of player action are
obtained for sports professionals’ training purposes. However,
the complex and dynamic background of sports videos and the
complexity of player actions bring considerable difficulty to the
automatic analysis. To fulfill such a challenging task, robust
algorithms including global motion estimation with adaptive out-
liers filtering, object segmentation based on adaptive background
construction, and automatic human body tracking are proposed
in this paper. Two visual analyzing tools: motion panorama and
overlay composition, are also introduced. Real diving and jump
game videos are used to test the proposed system and algorithms,
and the extensive and encouraging experimental results show
their effectiveness.
Index Terms—Action recognition, human body tracking, sports
training, video analysis, video object segmentation.
I. Introduction
W
ITH THE EXPLOSIVE growth of digital videos in
our daily life, automatic video content analysis has
become a basic requirement for efficient indexing and retrieval
of long video sequences. In recent years, the analysis of sports
videos has attracted great attention due to its mass appeal
and tremendous commercial potentials. Many works have been
conducted and technologies and systems have been developed
for automatic or semi-automatic parsing the structure of sports
Manuscript received October 9, 2008; revised May 10, 2009. First version
published November 3, 2009; current version published March 5, 2010. This
work was supported in part by the National Basic Research Program of China
(Grant No. 2007CB311100), and the Co-building Program of the Beijing
Municipal Education Commission. This paper was recommended by Associate
Editor T. Fujii.
H. Li is with the School of Software, Dalian University of Technology,
Dalian 116620, China.
J. Tang is with the School of Computing, National University of Singapore,
117590 Singapore (e-mail: tangjh@comp.nus.edu.sg).
S. Wu is with France Telecom Research and Development Beijing, Beijing
100080, China.
Y. Zhang and S. Lin are with the Institute of Computing Technology,
Chinese Academy of Sciences, Beijing 100080, China.
Color versions of one or more of the figures in this paper are available
online at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TCSVT.2009.2035833
video [1], [2], semantic events detection and video summariza-
tion [3], [4], enhanced sports TV broadcasting [5], and content
insertion [6]. The difficulty of video analysis is the semantic
gap between the low-level audio-visual features and high-level
concepts. To bridge the gap, some mid-level representations
are constructed based on low-level features with clustering
or classification methods [7]. However, these representations
are extracted from frame-based approaches and have no direct
link to high-level semantics. Moreover, they can only deduce
coarse-level knowledge of the video contents for general user
viewing purposes. Object’s behavior is another type but more
effective mid-level representation for video content analysis
[8], [9]. At the same time, for sports professionals such as
coachers and players, it is desired for finer granularity analysis
to get more detailed information such as action names, match
tactics, kinematical, or biometric measurements from videos
for coaching assistant and performance improvements. For ex-
ample, by automatically recognizing the actions and obtaining
player body joint angles in diving game videos, the coaches or
players can easily retrieve and compare qualitatively or quan-
titatively the performed actions with the same ones performed
by elite players in video database, and then improve their
performance in later training or competition. To these ends,
this paper addresses the automatic detection, recognition, and
analysis of player actions from broadcast sports game videos
or videos recorded during daily training. More specifically,
we focus on one sports genre where the player performs
his or her action in a large arena and the camera needs to
be operated with pan/tilt/zoom to capture the player in the
middle of the image. Usually, one or more cameras are placed
in the side-view to record the entire detailed action. This
includes a broad category of individual sports videos, such
as diving, jumps, gymnastics videos, and so on (see Fig. 1).
For such kind of action-critical sports videos, general users
would like to rapidly locate and watch the highlights, namely,
the video clips containing the desired action, while sports
professionals will be more interested in the performances of
the players. Manual analysis of sports videos to achieve such
aims is labor-intensive and time-consuming. Therefore, the
systems and techniques that can automatically parse long time
videos into browse-able actions and further provide kinematic
measurements for performance analysis are demanding.
In this paper,we present an integrated coarse-to-fine sports
video analysis system and various robust algorithms. Diving
videos are used as case study to demonstrate the effectiveness
of the system and algorithms due to the following motivations:
1051-8215/$26.00
c
2010 IEEE

剩余13页未读,继续阅读
资源评论


huangjie817
- 粉丝: 0
- 资源: 8









最新资源
- 办工,日常生活中电脑中的磁盘清理功能,可以查找本机的指定大小文件,非常方便!
- cuda-使用cuda并行加速实现之gemv.zip
- cuda-使用cuda并行加速实现之softmax.zip
- 基于Opencv的车牌识别系统
- cuda-使用cuda并行加速实现之reduce.zip
- 基于Protel 99se 超级元件库电子器件芯片库原理图库2MB(810个)+PCB封装库10MB(1240个)合集.zip
- mmexport1713919112597.jpg
- cuda-使用cuda并行加速实现之kmeans聚类算法的实现.zip
- web-work-2024-4-24
- cuda-使用cuda并行加速实现之UpsampleNearest2D.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


