




数 据 结 构
实
验
报
告
实验名称:哈夫曼树
学生姓名:XXX
班 级:XX
班内序号:XX
学 号:XX
日 期:2014 年 12 月
第 1 页

1. 实验目的和内容
利用二叉树结构实现哈夫曼编/解码器。
基本要求:
1、 初始化(Init):能够对输入的任意长度的字符串 s 进行统计,统计每个字
符的频度,
并建立哈夫曼树
2、 建立编码表(CreateTable):利用已经建好的哈夫曼树进行编码,并将每
个字符的编码输出。
3、 编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的
字符串输
出。
4、 译码(Decoding):利用已经建好的哈夫曼树对编码后的字符串进行译码,
并输出
译码结果。
5、 打印(Print):以直观的方式打印哈夫曼树(选作)
6、 计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编
码的压
缩效果。
7、 可采用二进制编码方式(选作)
测试数据:
I love data Structure, I love Computer。I will try my best to study data Structure.
提示:
1、用户界面可以设计为“菜单”方式:能够进行交互。
2、根据输入的字符串中每个字符出现的次数统计频度,对没有出现的字符
一律不用编码
2. 程序分析
2.1 存储结构
用 struct 结构类型来实现存储
树的结点类型
第 2 页
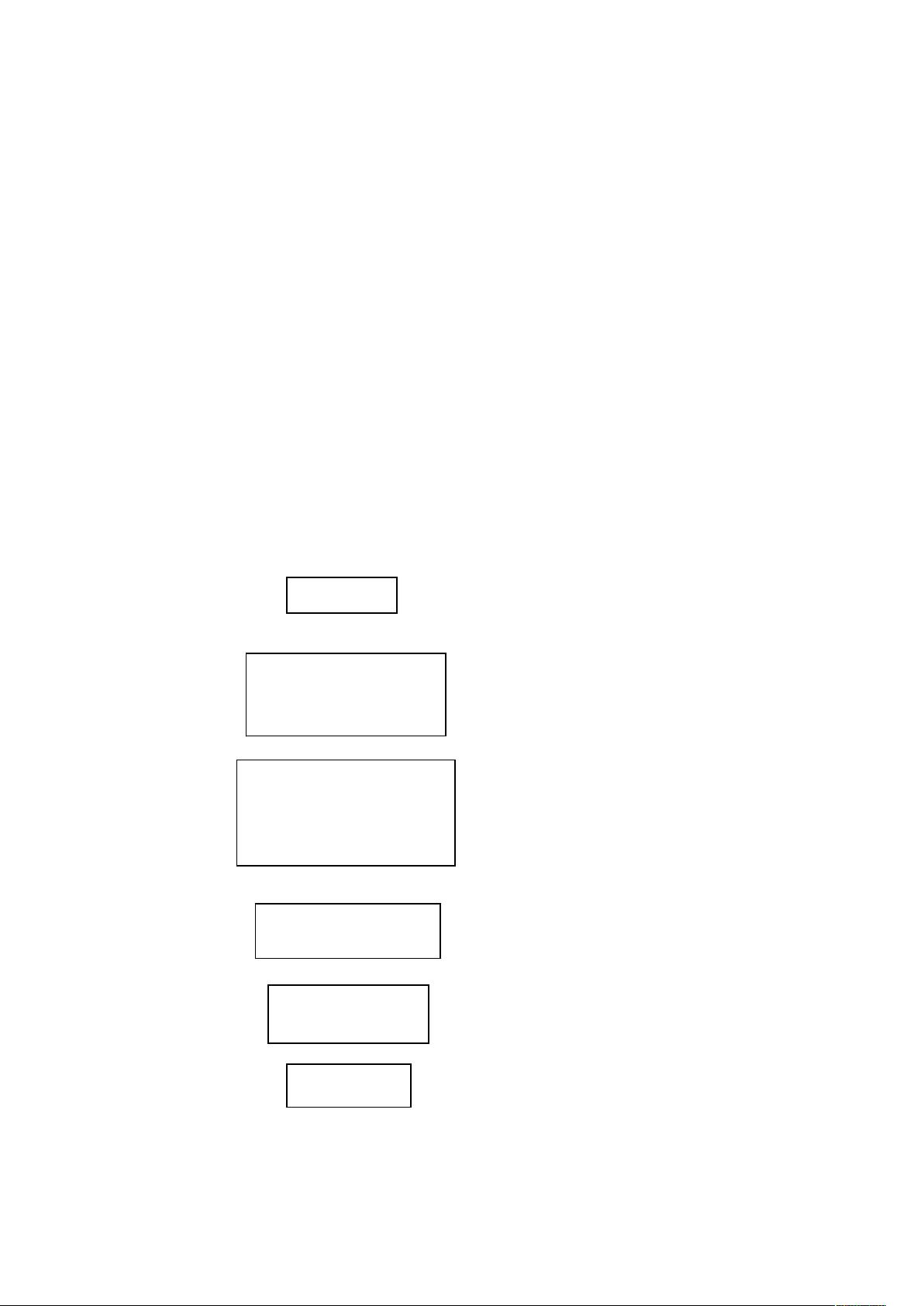
struct HNode
{
int weight; //权值
int parent; //父节点
int lchild; //左孩子
int rchild; //右孩子
};
struct HCode //实现编码的结构类型
{
char data; //被编码的字符
char code[100]; //字符对应的哈夫曼编码
};
2.2 程序流程
第 3 页
输入字符串
统计出现的字符种类和
次数,构建权值数组,
初始化树结点与编码表
根据哈夫曼构建规则构建
哈夫曼树,根据编码规则
对出现字符进行编码 ,构
建编码表
将输入的 字符挨个 编
码
对编码后的字符进
行解码
分析存储大小

2.3 关键算法分析
算法 1:void Huffman::Count()
[1] 算法功能:对出现字符的和出现字符的统计,构建权值结点,初始化编码表
[2] 算法基本思想:对输入字符一个一个的统计,并统计出现次数,构建权值数组,
[3] 算法空间、时间复杂度分析:空间复杂度 O(1),要遍历一遍字符串,时间复
杂度 O(n)
[4] 代码逻辑:
leaf=0; //初始化叶子节点个数
int i,j=0;
int s[128]={0}; 用于存储出现的字符
for(i=0;str[i]!='\0';i++) 遍历输入的字符串
s[(int)str[i]]++; 统计每个字符出现次数
for(i=0;i<128;i++)
if(s[i]!=0)
{
data[j]=(char)i; 给编码表的字符赋值
weight[j]=s[i]; 构建权值数组
j++;
}
leaf=j; //叶子节点个数即字符个数
for(i=0;i<leaf;i++)
cout<<data[i]<<"的权值为:"<<weight[i]<<endl;
算法 2:void Init();
[1] 算法功能:构建哈弗曼树
[2] 算法基本思想:根据哈夫曼树构建要求,选取权值最小的两个结点结合,新结点
加入数组,再继续选取最小的两个结点继续构建。
[3] 算法空间、时间复杂度分析:取决于叶子节点个数,时间复杂度 O(n),空间
复杂度 O(1)
[4] 代码逻辑
HTree=new HNode[2*leaf-1]; n2=n0-1,一共需要 2n-1 个结点空间
第 4 页













评论0