十五个经典算法研究与总结、目录+索引


1
十五个经典算法研究与总结
作者:July
时间:2010 年 12 月末-2011 年 12 月。
微博:http://weibo.com/julyweibo
出处:http://blog.csdn.net/v_JULY_v
声明:版权所有,侵权定究。
文档制作者:花明月暗 & 有鱼网 http://www.youyur.com/CEO吴超
前言:
本人的原创作品经典算法研究系列,自从10年12月末至11年12月,写了近一年。
可以这么说,开博头俩个月一直在整理微软等公司的面试题,而后的四个月至今,则断断续
续,除了继续微软面试100题系列,和程序员编程艺术系列之外,便在写这经典算法研究
系列和相关算法文章。
本经典算法研究系列,涵盖 A*.Dijkstra.DP.BFS/DFS.红黑树.KMP.遗传.启发式搜索.图像
特征提取 SIFT.傅立叶变换.Hash.快速排序.SPFA.快递选择 SELECT 等 15 个经典基础算法,
共计 31 篇文章,包括算法理论的研究与阐述,及其编程的具体实现。很多个算法都后续写
了续集,如第二个算法:Dijkstra 算法,便写了 4 篇文章;sift 算法包括其编译及实现,写
了 5 篇文章;而红黑树系列,则更是最后写了 6 篇文章,成为了国内最为经典的红黑树教程。
OK,任何人有任何问题,欢迎随时在 blog 上留言评论,或来信:zhoulei0907@yahoo.cn
批评指正。谢谢。以下是已经写了的 15 个经典算法集锦,算是一个目录+索引,共计 31 篇
文章:
十五个经典算法研究集锦+目录
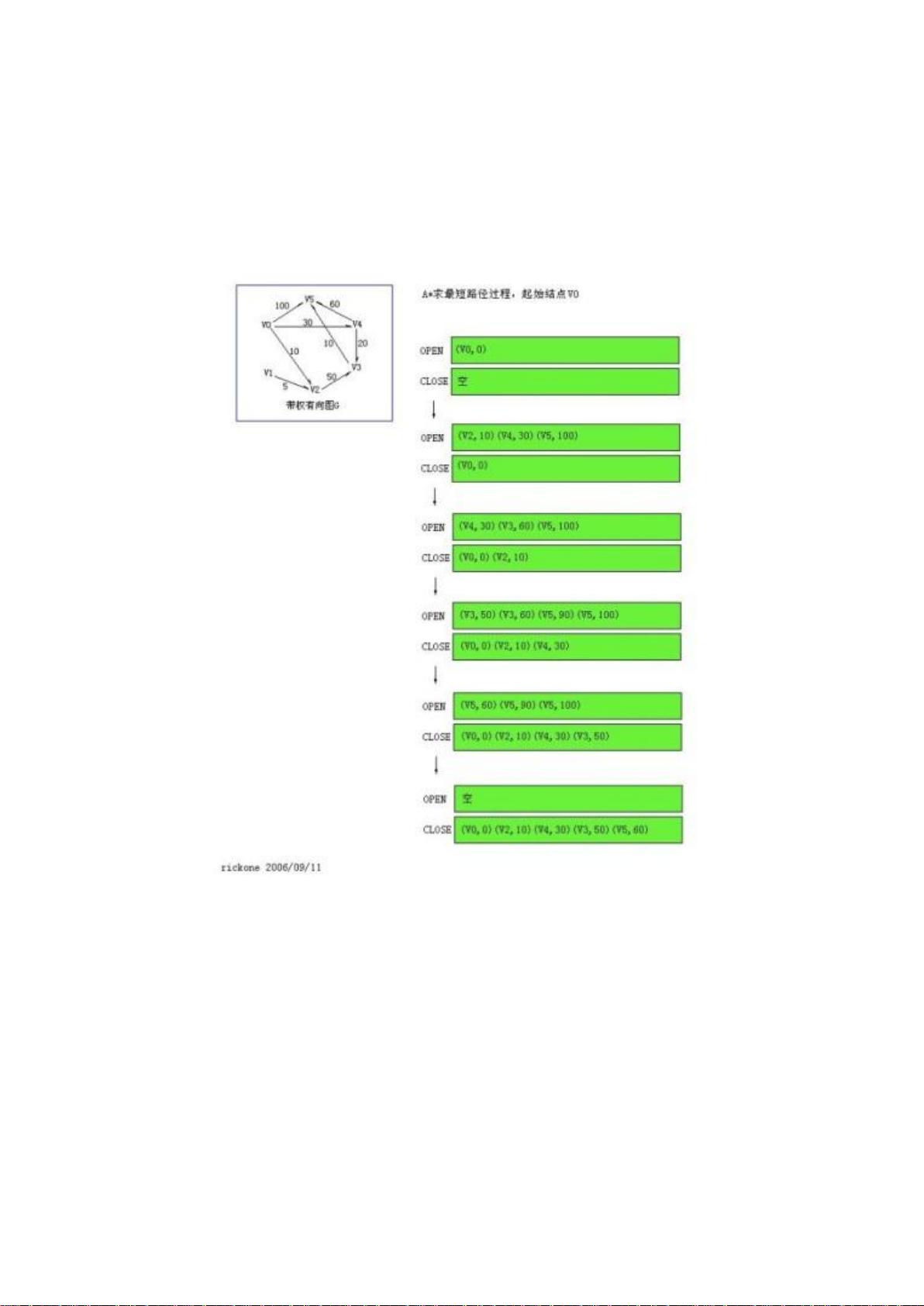
一、A*搜索算法
一(续)、A*,Dijkstra,BFS 算法性能比较及 A*算法的应用
二、Dijkstra 算法初探
二(续)、彻底理解 Dijkstra 算法
二(再续)、Dijkstra 算法+fibonacci 堆的逐步 c 实现
二(三续)、Dijkstra 算法+Heap 堆的完整 c 实现源码
三、动态规划算法
四、BFS 和 DFS 优先搜索算法
五、教你透彻了解红黑树 (红黑数系列六篇文章之其中两篇)
五(续)、红黑树算法的实现与剖析
六、教你初步了解 KMP 算法、updated (KMP 算法系列三篇文章)
六(续)、从 KMP 算法一步一步谈到 BM 算法
六(三续)、KMP 算法之总结篇(必懂 KMP)
七、遗传算法 透析 GA 本质
八、再谈启发式搜索算法
九、图像特征提取与匹配之 SIFT 算法 (SIFT 算法系列五篇文章)
九(续)、sift 算法的编译与实现



剩余462页未读,继续阅读
资源评论

 harderc1112014-04-27很好 有助于学习
harderc1112014-04-27很好 有助于学习 xiyingkejia2014-01-02这个资源还好。有助于学习。谢谢。
xiyingkejia2014-01-02这个资源还好。有助于学习。谢谢。 luxiao66662014-07-16讲的很全面 收藏了 作为今后基础学习的材料
luxiao66662014-07-16讲的很全面 收藏了 作为今后基础学习的材料

力都
- 粉丝: 1
- 资源: 5









最新资源
- 高等数学第一章第二节数列的极限
- Python 版冒泡排序算法源代码
- tensorflow-gpu-2.7.2-cp38-cp38-manylinux2010-x86-64.whl
- tensorflow-2.7.3-cp39-cp39-manylinux2010-x86-64.whl
- tensorflow-2.7.2-cp39-cp39-manylinux2010-x86-64.whl
- Python版本快速排序源代码
- Python 语言版的快速排序算法实现
- 450815388207377安卓_base.apk
- 超微主板 X9DRE-TF+ bios 支持 nvme启动
- 基于Python通过下载气象数据和插值拟合离散数据曲线实现对寒潮过程的能量分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


