Outrageously Large Neural Networks: The Sparsely-Gated Mixture-o...
需积分: 0 140 浏览量
2017-06-23
20:32:54
上传
评论
收藏 532KB PDF 举报


Under review as a conference paper at ICLR 2017
OUTRAGEOUSLY LARGE NEURAL NETWORKS:
THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
Noam Shazeer
1
, Azalia Mirhoseini
∗†1
, Krzysztof Maziarz
∗2
, Andy Davis
1
, Quoc Le
1
, Geoffrey
Hinton
1
and Jeff Dean
1
1
Google Brain, {noam,azalia,andydavis,qvl,geoffhinton,jeff}@google.com
2
Jagiellonian University, Cracow, krzysztof.maziarz@student.uj.edu.pl
ABSTRACT
The capacity of a neural network to absorb information is limited by its number of
parameters. Conditional computation, where parts of the network are active on a
per-example basis, has been proposed in theory as a way of dramatically increas-
ing model capacity without a proportional increase in computation. In practice,
however, there are significant algorithmic and performance challenges. In this
work, we address these challenges and finally realize the promise of conditional
computation, achieving greater than 1000x improvements in model capacity with
only minor losses in computational efficiency on modern GPU clusters. We in-
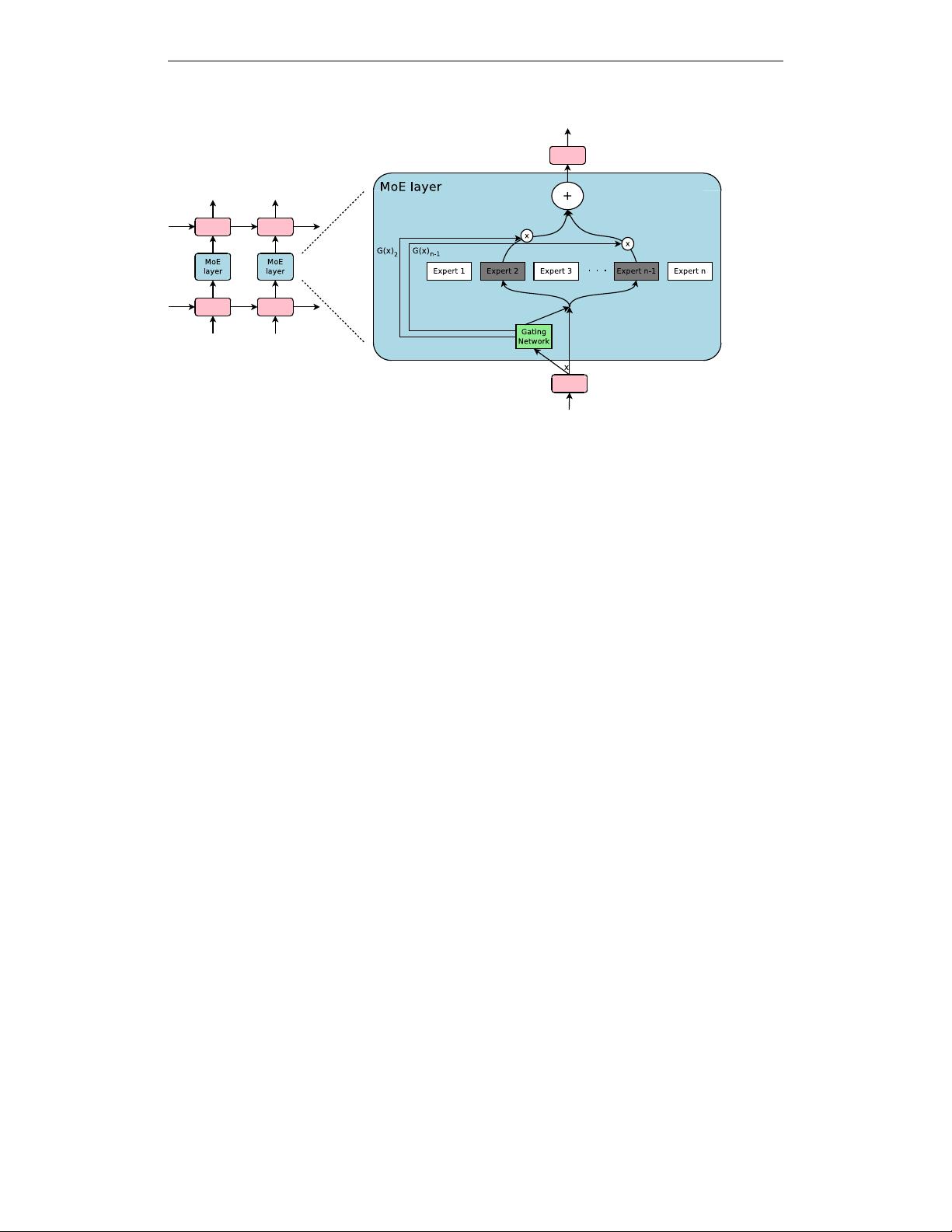
troduce a Sparsely-Gated Mixture-of-Experts layer (MoE), consisting of up to
thousands of feed-forward sub-networks. A trainable gating network determines
a sparse combination of these experts to use for each example. We apply the MoE
to the tasks of language modeling and machine translation, where model capacity
is critical for absorbing the vast quantities of knowledge available in the training
corpora. We present model architectures in which a MoE with up to 137 billion
parameters is applied convolutionally between stacked LSTM layers. On large
language modeling and machine translation benchmarks, these models achieve
significantly better results than state-of-the-art at lower computational cost.
1 INTRODUCTION AND RELATED WORK
1.1 CONDITIONAL COMPUTATION
Exploiting scale in both training data and model size has been central to the success of deep learn-
ing. When datasets are sufficiently large, increasing the capacity (number of parameters) of neural
networks can give much better prediction accuracy. This has been shown in domains such as text
(Sutskever et al., 2014; Bahdanau et al., 2014; Jozefowicz et al., 2016; Wu et al., 2016), images
(Krizhevsky et al., 2012; Le et al., 2012), and audio (Hinton et al., 2012; Amodei et al., 2015). For
typical deep learning models, where the entire model is activated for every example, this leads to
a roughly quadratic blow-up in training costs, as both the model size and the number of training
examples increase. Unfortunately, the advances in computing power and distributed computation
fall short of meeting such demand.
Various forms of conditional computation have been proposed as a way to increase model capacity
without a proportional increase in computational costs (Davis & Arel, 2013; Bengio et al., 2013;
Eigen et al., 2013; Ludovic Denoyer, 2014; Cho & Bengio, 2014; Bengio et al., 2015; Almahairi
et al., 2015). In these schemes, large parts of a network are active or inactive on a per-example
basis. The gating decisions may be binary or sparse and continuous, stochastic or deterministic.
Various forms of reinforcement learning and back-propagation are proposed for trarining the gating
decisions.
∗
Equally major contributors
†
Work done as a member of the Google Brain Residency program (g.co/brainresidency)
1
arXiv:1701.06538v1 [cs.LG] 23 Jan 2017


剩余18页未读,继续阅读
资源评论













